[[Abstract]]
- Advertising and feed ranking are essential to many Internet companies such as Facebook and Sina Weibo. Among many real-world advertising and feed ranking systems, click through rate (CTR) prediction plays a central role. There are many proposed models in this field such as logistic regression, tree based models, factorization machine based models and deep learning based CTR models. However, many current works calculate the feature interactions in a simple way such as Hadamard product and inner product and they care less about the importance of features. In this paper, a new model named FiBiNET as an abbreviation for Feature Importance and Bilinear feature Interaction NETwork is proposed to dynamically learn the feature importance and fine-grained feature interactions. On the one hand, the FiBiNET can dynamically learn the importance of features via the Squeeze-Excitation network (SENET) mechanism; on the other hand, it is able to effectively learn the feature interactions via bilinear function. We conduct extensive experiments on two realworld datasets and show that our shallow model outperforms other shallow models such as factorization machine(FM) and field-aware factorization machine(FFM). In order to improve performance further, we combine a classical deep neural network(DNN) component with the shallow model to be a deep model. The deep FiBiNET consistently outperforms the other state-of-the-art deep models such as DeepFM and extreme deep factorization machine(XdeepFM).
[[Attachments]]
创新点 #card
- 使用 SENET 层对 embedding 进行加权
- 使用 Bilinear-Interaction Layer 进行特征交叉
背景
- importance of features and feature interactions
网络结构 #card
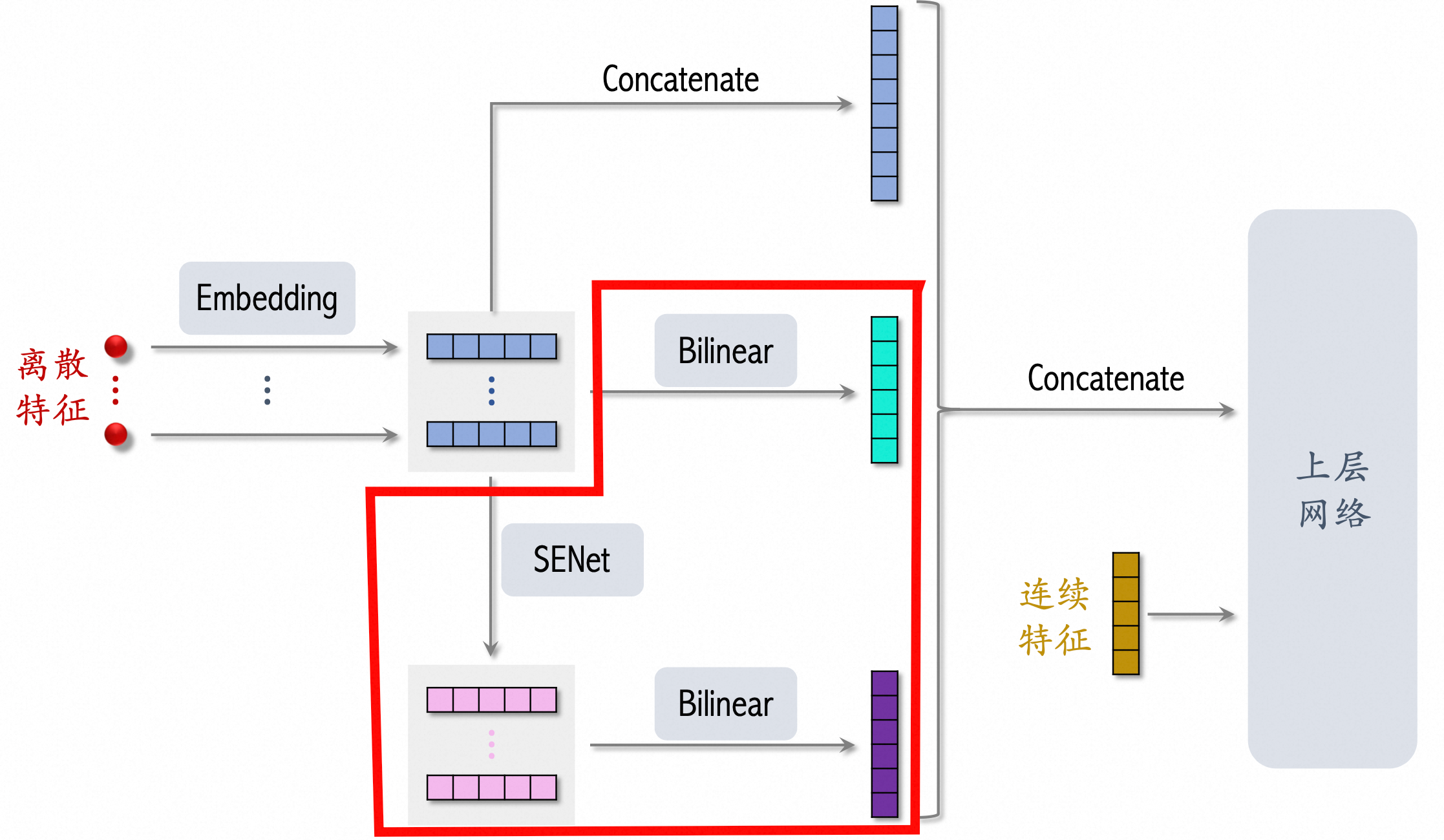
[[SENET]] Squeeze-and-Excitation network 特征加权方法
- Squeeze
f*k 压缩成 f*1
- Excitation 然后通过两层 dnn 变成得到权重
f*1
- Re-Weight 将结果和原始
f*k 相乘。
- 原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
[[Bilinear-Interaction Layer]] → 结合Inner Product和Hadamard Product方式,并引入额外参数矩阵W,学习特征交叉。
- 不同特征之间交叉
v_i * W * v_j 时,权重矩阵来源
- Field-All Type → 全体共享 W
- 参数量 →
feature * embedding + emb*emb
- Field-Each Type → 每个 filed 一组 W
- 参数量 →
feature * embedding + feature*emb*emb
- Filed-Interaction Type → 不同特征之间有一组 w
- 参数量 →
feature * embedding + feature*feature*emb*emb
- Bilinear-Interaction Layer 对比 [[FFM]] 有效减少参数量
- FM 参数量 →
feature * embedding
- FFM 参数量 →
feature * filed * embedding
- 不同特征交叉方式
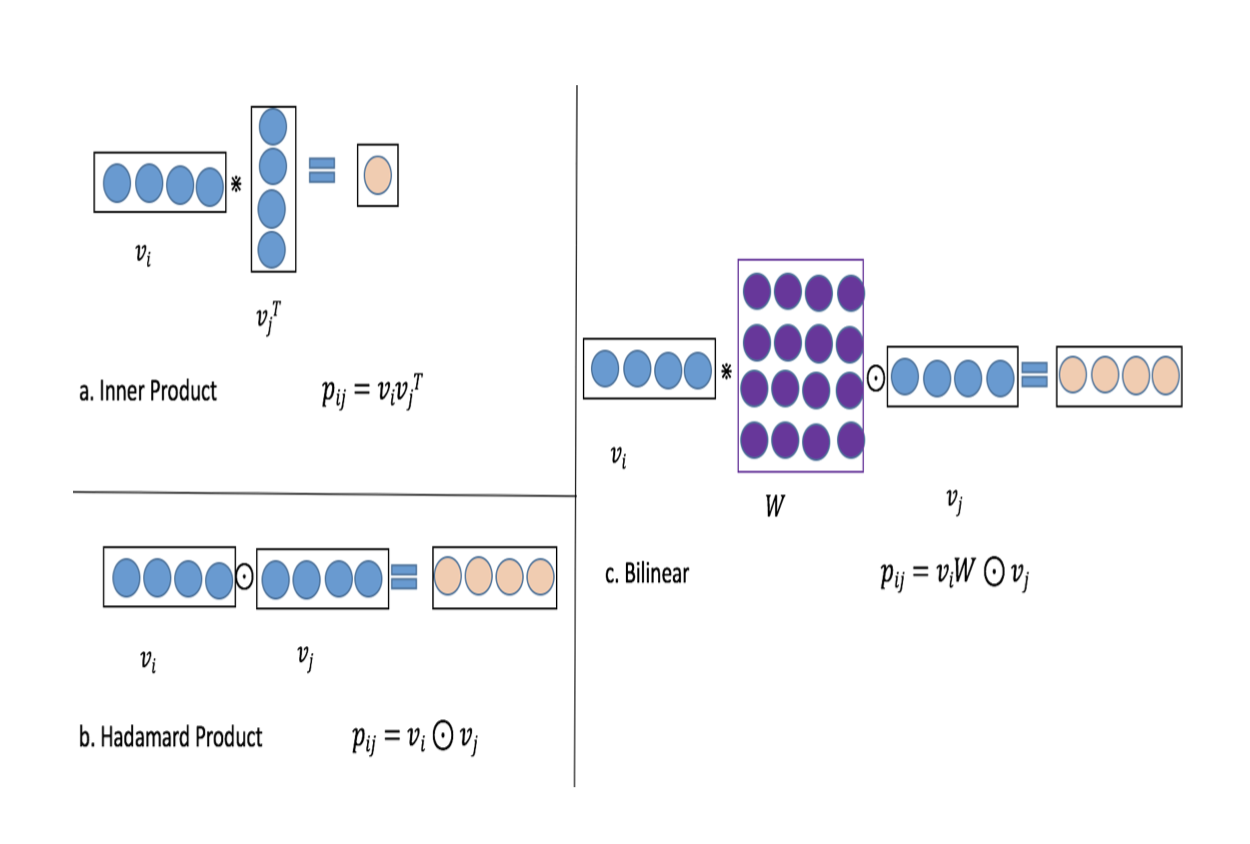
[[ETA]] fm 交叉部分可以尝试引入 bi layer,使用 link 状态组合 W。
Ref