[[@BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding]]
代码:google-research/bert: TensorFlow code and pre-trained models for BERT
大模型 + 微调提升小任务的效果
输入层
BERT
两种 NLP 预训练
[[ELMo]]
[[GPT]]
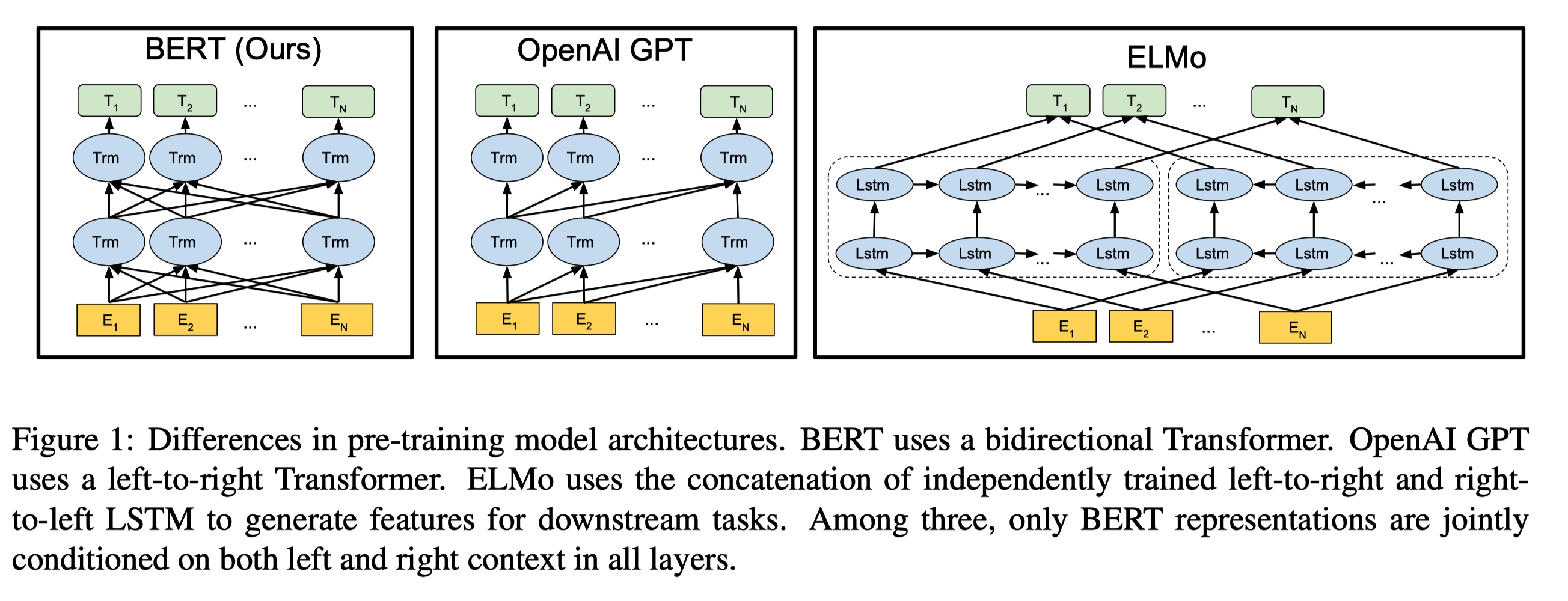
贡献性
模型输入:
训练方式
- [[Masked-Language Modeling]] →mask 部分单词,80 % mask,10 % 错误单词, 10% 正确单词
- 目的 → 训练模型记忆句子之间的关系。
- 减轻预训练和 fine-tune 目标不一致给模型带来的影响
- 目的 → 训练模型记忆句子之间的关系。
- [[Next Sentence Prediction]] → 预测是不是下一个句子
- 句子 A 和句子 B 有 50% 的概率是上下文
- 解决后续什么问题 → QA 和自然语言推理
[[激活函数]] [[GELU]]
优化器
fine tune
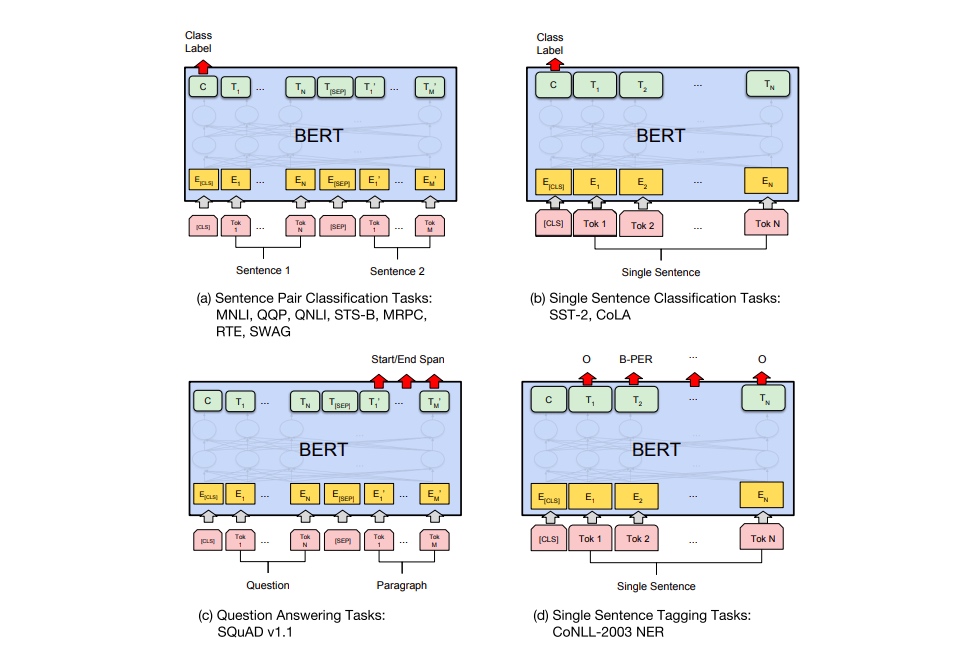
研究取不同的 embedding 效果
缺陷
[[Ref]]
- [[Multimodal BERT]]
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) – Jay Alammar – Visualizing machine learning one concept at a time
- 如何评价 BERT 模型? - 知乎
- NLP 从语言模型看Bert的善变与GPT的坚守 - 知乎
- 像Bert这样的双向语言模型为何要做 masked LM?[[GPT]] 为何一直坚持单向语言模型? Elmo 也号称双向,为何不需要 mask?[[Word2Vec]] 的 CBOW 为何也不用 mask?
- indirectly see themselves
- GPT 保留用上文生成下文的能力
- 为什么 Bert 的三个 Embedding 可以进行相加? - 知乎
- 三个 embedding 相加和拼接
- 联系 → 三个 embedding 相加相当于三个原始的 one-hot 拼接再经过一个全连接网络。
- 优点 → 和拼接相比,相加可以节约模型参数。
- 实验显示拼接并没有相加效果好,拼接后维度增加,需要再经过一个线性变换降低维度,增加了更多参数。
- 联系 → 三个 embedding 相加相当于三个原始的 one-hot 拼接再经过一个全连接网络。
- 之前的理解和多个波长不同的波相加,最后还是能分离出来,所以模型也应该能区分。
- 空间维度很高,模型能区分各个组分
- 参数空间量 30k2512
- 模型表达能力至少是 2^768
- 梯度角度,
(f + g +h)' = f' + g' + h'
- 三个 embedding 相加和拼接
- BERT—容易被忽视的细节
- 细节三:对于任务一,对于在数据中随机选择 15% 的标记,其中80%被换位[mask],10%不变、10%随机替换其他单词,原因是什么?#card
- [mask] 在 fine-tune 任务中不会出现,模型不知道如何处理。
- 缓解上面的现象
- 15% 标记被预测,需要更多训练步骤来收敛
- 细节三:对于任务一,对于在数据中随机选择 15% 的标记,其中80%被换位[mask],10%不变、10%随机替换其他单词,原因是什么?#card
 {:height 198, :width 509}
{:height 198, :width 509}