年中的时候,想把自己写的一些笔记更好的管理起来。最初想到的是搭建 wiki ,实现知识的网状化连接。不过市面上常用的一些个人 wiki 方案都不是很满意。最终选择 hexo 搭配一个 wiki 主题 Wikitten。另外,后来了解到有一种基于纯文本的知识管理方案:zettelkasten。感兴趣的可以去看一下。
写日记是这么多年以来坚持的一件小事情。之前一直是在笔记本上写,后来慢慢的尝试通过印象笔记来写。2月份,订阅 Day One ,开始尝试迁移到它上面去。作为一个专业的软件,体验真的比之前的方式不知道好多少。Day One 上也有很多数据统计,多少可以拿来得瑟用。另外,自己干的一件事情就是把印象笔记中的日记慢慢转移到 Day one 。写在笔记本上的日记,也被我拍成一张又一张的照片,只不过这个迁移起来比较麻烦。
Linear SVM: classifier is an option for solving the image classification problem, but the curse of dimensions makes it stop improving at some point. @todo
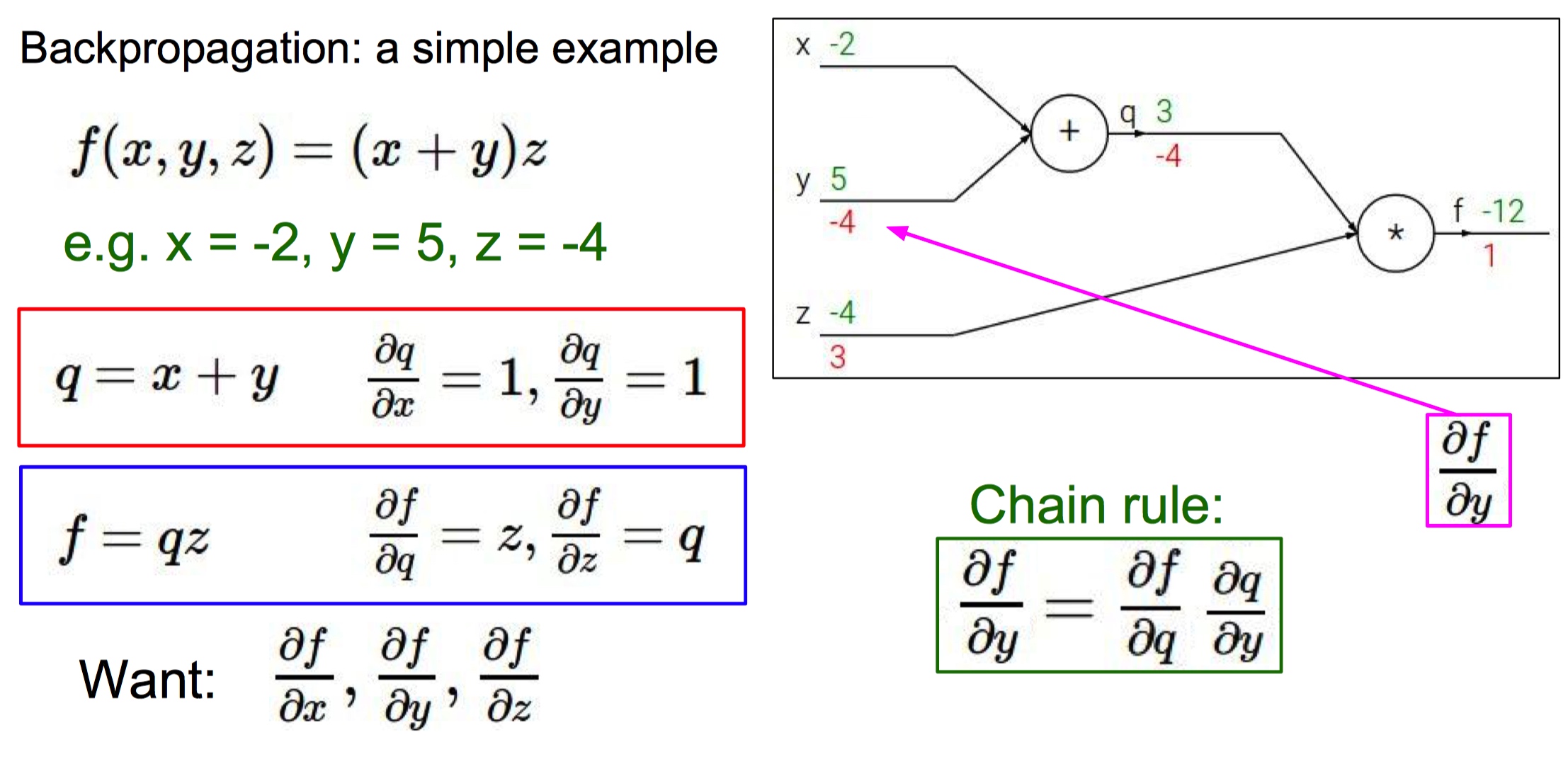
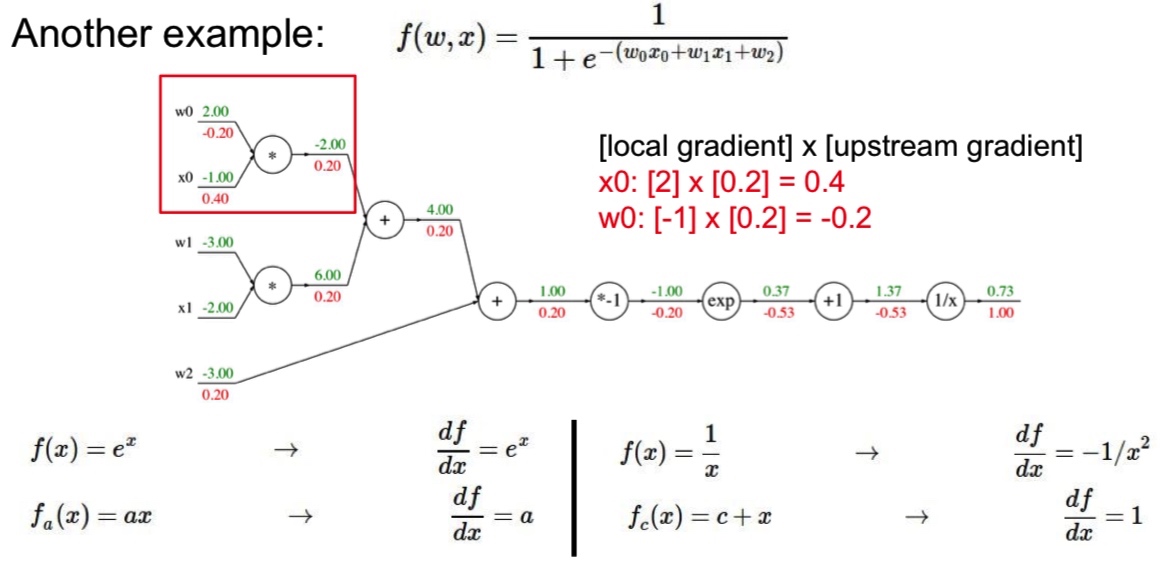
classMultuplyGate(object): """ x,y are scalars """ defforward(x,y): z = x*y self.x = x # Cache self.y = y # Cache # We cache x and y because we know that the derivatives contains them. return z defbackward(dz): dx = self.y * dz #self.y is dx dy = self.x * dz return [dx, dy]
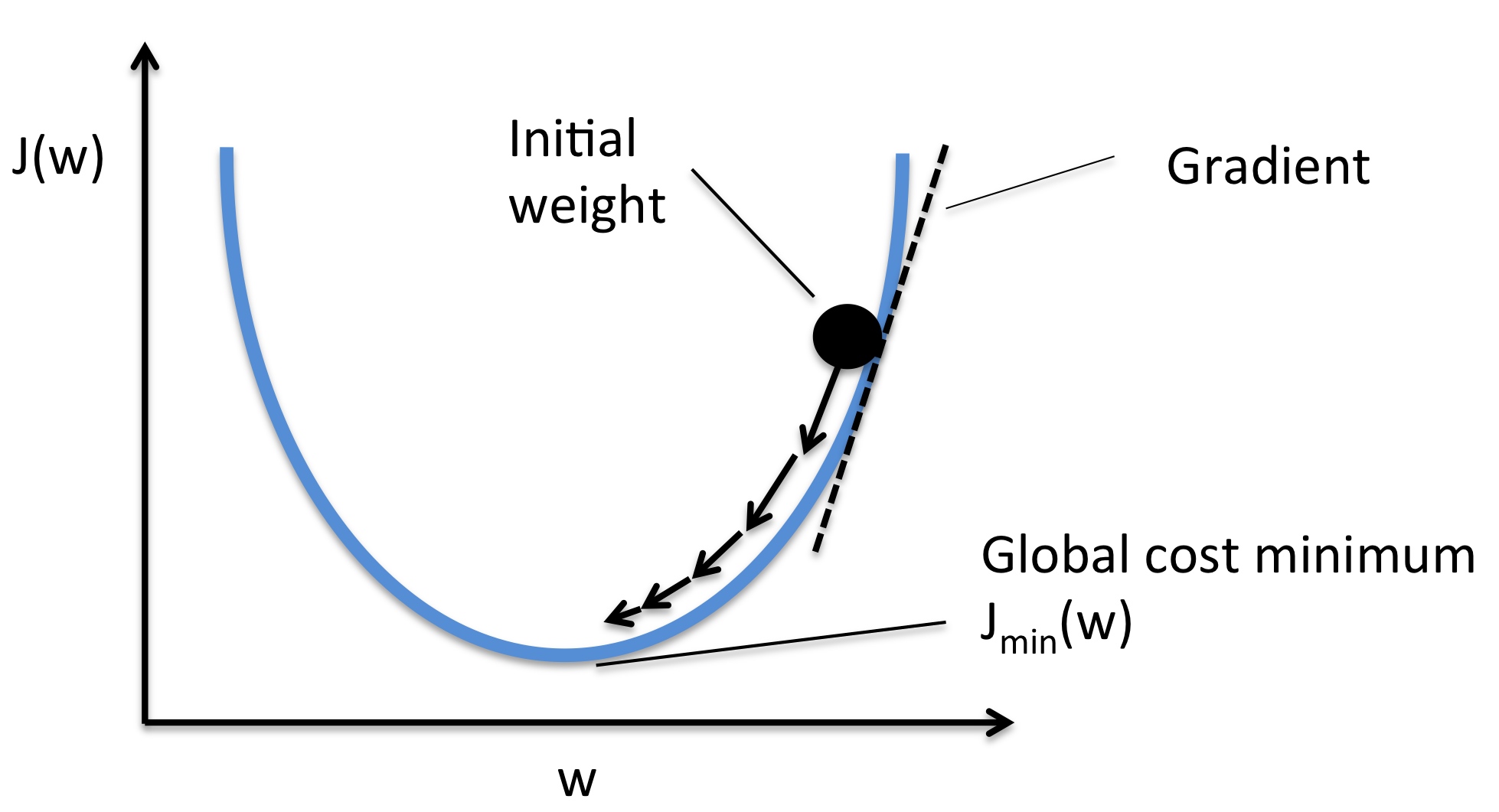
It calculates an exponentially weighted average of past gradients, and stores it in variables v (before bias correction) and vcorrected (with bias correction).
It calculates an exponentially weighted average of the squares of the past gradients, and stores it in variables s (before bias correction) and scorrected (with bias correction).
一阶到导数累积,二阶导数累积
It updates parameters in a direction based on combining information from “1” and “2”.
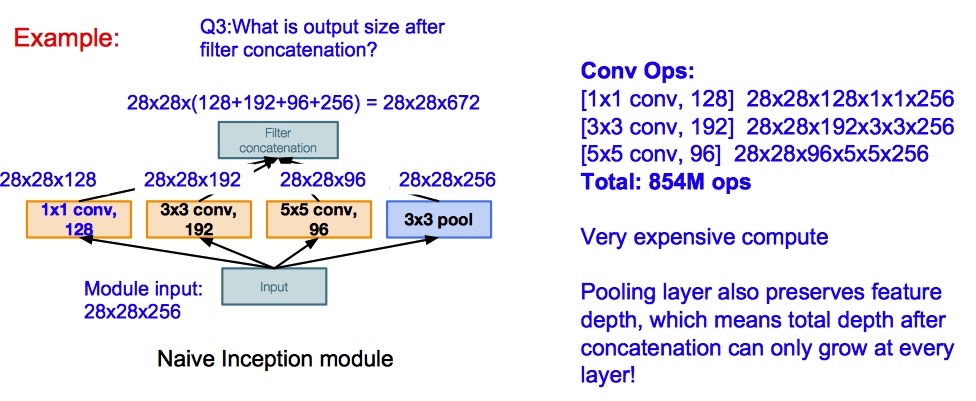
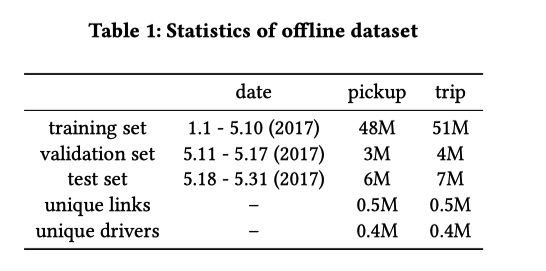
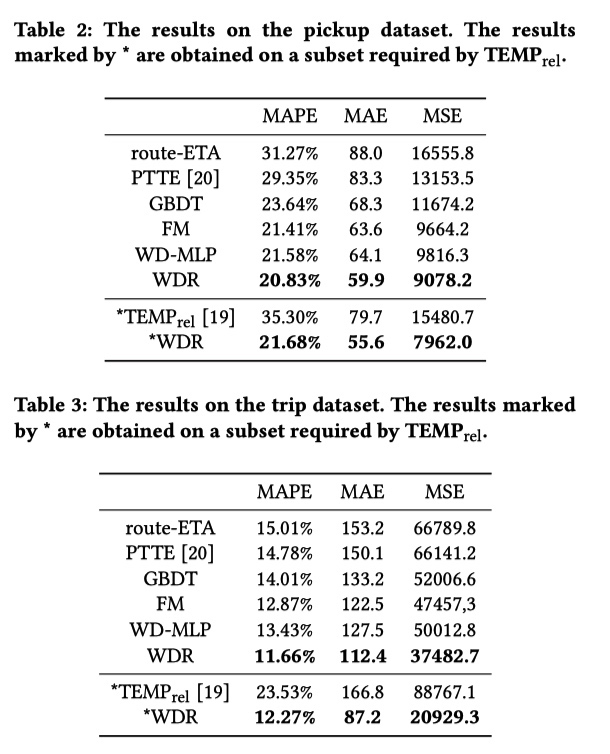
这篇论文是滴滴时空数据组 2018 年在 KDD 上发表的关于在 ETA 领域应用深度学习的文章,里面提到模型和技巧大家都应该耳熟能详,最大亮点是工业界的创新。
简单介绍一下背景:ETA 是 Estimate Travel Time 的缩写,中文大概能翻译成到达时间估计。这个问题描述是:在某一个时刻,估计从 A 点到 B 点需要的时间。对于滴滴,关注的是司机开车把乘客从起点送到终点需要的时间。抽象出来 ETA 就是一个时间空间信息相关的回归问题。CTR 中常用的方法都可以在这里面尝试。
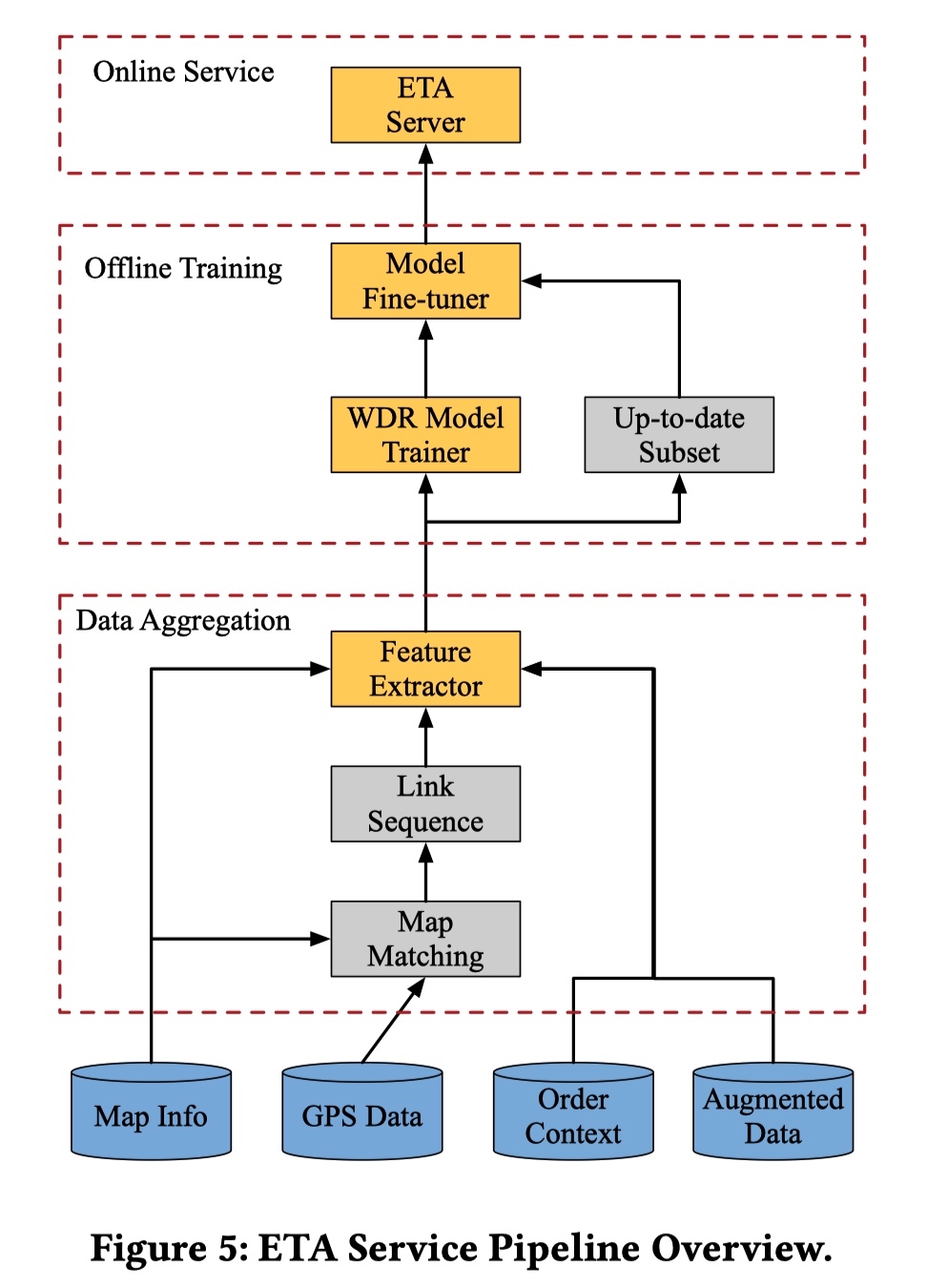
对于这个问题:文章首先提到一个最通用的方法 Route ETA:即在获得 A 点到 B 点路线的情况下,计算路线中每一段路的行驶时间,并且预估路口的等待时间。最终 ETA 由全部时间相加得到。这种方法实现起来很简单,也能拿到一些收益。但是仔细思考一下,没有考虑未来道路的通行状态变化情况以及路线的拓扑关系。针对这些问题,文章中提到滴滴内部也有利用 GBDT 或 FM 的方法解决 ETA 问题,不过没有仔细写实现的方法,我也不好继续分析下去。
评价指标
对于 ETA 问题来说,工业界和学术界常用的指标是 MAPE(mean absolute percentage error),yi 是司机实际从 A 点到 B 点花费的时间,f(xi) 是 ETA 模型估计出来的时间。得到计算公式如下:
minfi=1∑Nyi∣yi−f(xi)∣
多说一句,如果使用 GBDT 模型实现 ETA 时,这个损失函数的推导有点困难,全网也没有看见几个人推导过。
FMA-ETA: Estimating Travel Time Entirely Based on FFN With Attention
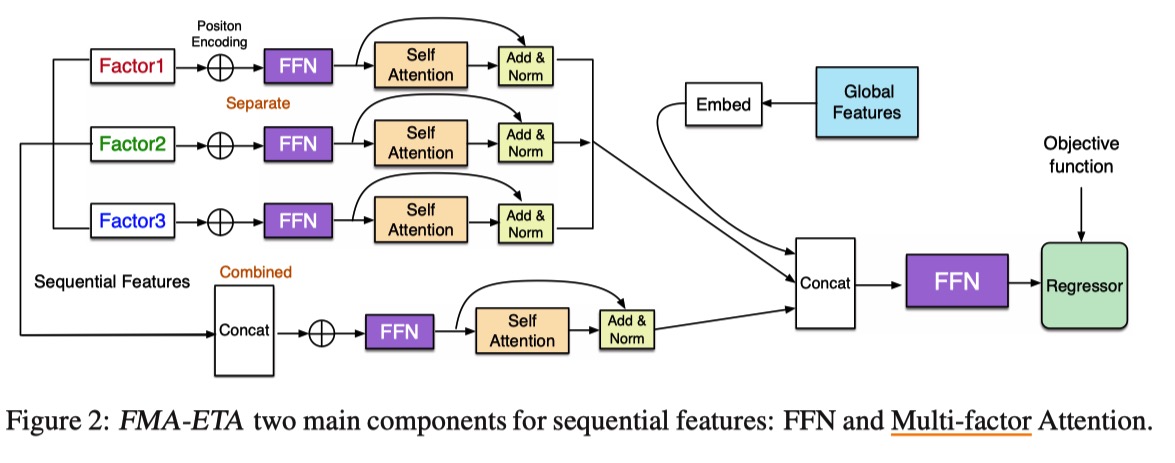
WDR 模型中 RNN 耗时长,探索基于 Attention 机制的模型
对特征分组(multi-factor)去做 Attention 效果比多头要好
实验结果分析这部分没有看懂
The deep modules with attention achieve better results than WDR on MAE and RMSE metrics, which means attention mechanism can help to extract features and sole the long-range dependencies in long sequence.
遗憾之处
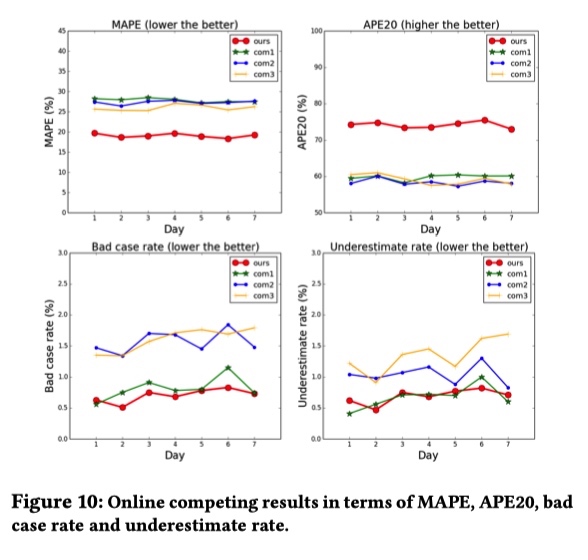
新模型预测时延减少,但是没有线上实验结果。
暂时没有公开代码和数据集。
总结
从上面简单的介绍来看,ETA 可以使用 CTR 和 NLP 领域的很多技术,大有可为。最后,滴滴 ETA 团队持续招人中(社招、校招、日常实习等),感兴趣者快快和我联系。
8.同年大跃进,在滴滴中高层的眼里,没有BAT。滴滴单量超淘宝指日可待,GAFA才是滴滴要赶超的对象。百度系,LinkedIn系,学院派,uber帮,联想系,MBB就算了,据说连藤校都混成了一个小圈子。。一个项目A team ,B team。一个ETA,投入了多少人力自相残杀?MAPE做到0%又如何?用户体验就爆表了吗?长期留存就高枕无忧了吗?风流总被雨打风吹去,滴滴是二龙山,三虫聚首?是不是正确的事情不知道,反正跟着公司大势所趋,升D10保平安。
generalization 指的是通过泛化出现过特征从解释新出现特征的能力。常用的是将高维稀疏的特征转换为低维稠密 embedding 向量,然后使用 fm 或 dnn 等算法。与 LR 相比,减少特征工程的投入,而且对没有出现过的组合有较强的解释能力。但是当遇到的用户有非常小众独特的爱好时(对应输入的数据非常稀疏和高秩),模型会过度推荐。
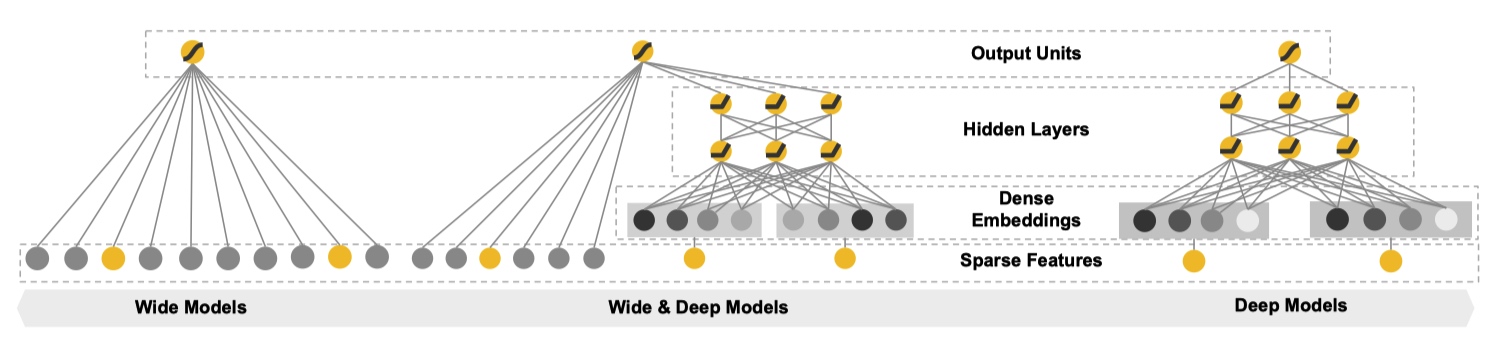
综合前文 ,作者提出一种新的模型 Wide & Deep。
模型
从文章题目中顾名思义,Wide & Deep 是融合 Wide Models 和 Deep Models 得到,下图形象地展示出来。
Wide Component 是由一个常见的广义线性模型:y=wTx+b。其中输入的特征向量 x 包括两种类型:原始输入特征(raw input features)和组合特征(transformed features)。
常用的组合特征公式如下:
ϕk(x)=i=1∏dxicki,cki∈{0,1}
cki 代表对于第k个组合特征是否包含第i个特征。xi是布尔变量,代表第i个特征是否出现。例如对于组合特征 AND(gender=female, language=en) 当且仅当 x 满足(“gender=female” and “language=en”)时,ϕk(x)=1。
Deep Component 是一个标准的前馈神经网络,每一个层的形式诸如:a(l+1)=f(W(l)a(l)+b(l))。对于输入中的 categorical feature 需要先转化成低维稠密的 embedding 向量,再和其他特征一起喂到神经网络中。
对于这种由基础模型组合得到的新模型,常用的训练形式有两种:joint training 和 ensemble。ensemble 指的是,不同的模型单独训练,且不共享信息(比如梯度)。只有在预测时根据不同模型的结果,得到最终的结果。相反,joint training 将不同的模型结果放在同一个损失函数中进行优化。因此,ensmble 要且模型独立预测时就有有些的表现,一般而言模型会比较大。由于 joint training 训练方式的限制,每个模型需要由不同的侧重。对于 Wide&Deep 模型来说,wide 部分只需要处理 Deep 在低阶组合特征学习的不足,所以可以使用简单的结果,最终完美使用 joint traing。
预测时,会将 Wide 和 Deep 的输出加权得到结果。在训练时,使用 logistic loss function 做为损失函数。模型优化时,利用 mini-batch stochastic optimization 将梯度信息传到 Wide 和 Deep 部分。然后,Wide 部分通过 FTRL + L1 优化,Deep 部分通过 AdaGrad 优化。