问题来了:为什么RL是work的,如何设计更有效的RL方法?
关于第一点,ds(deepseek)在少量数据上做RL微调就能很大程度上改善模型表现。实验结果如下图所示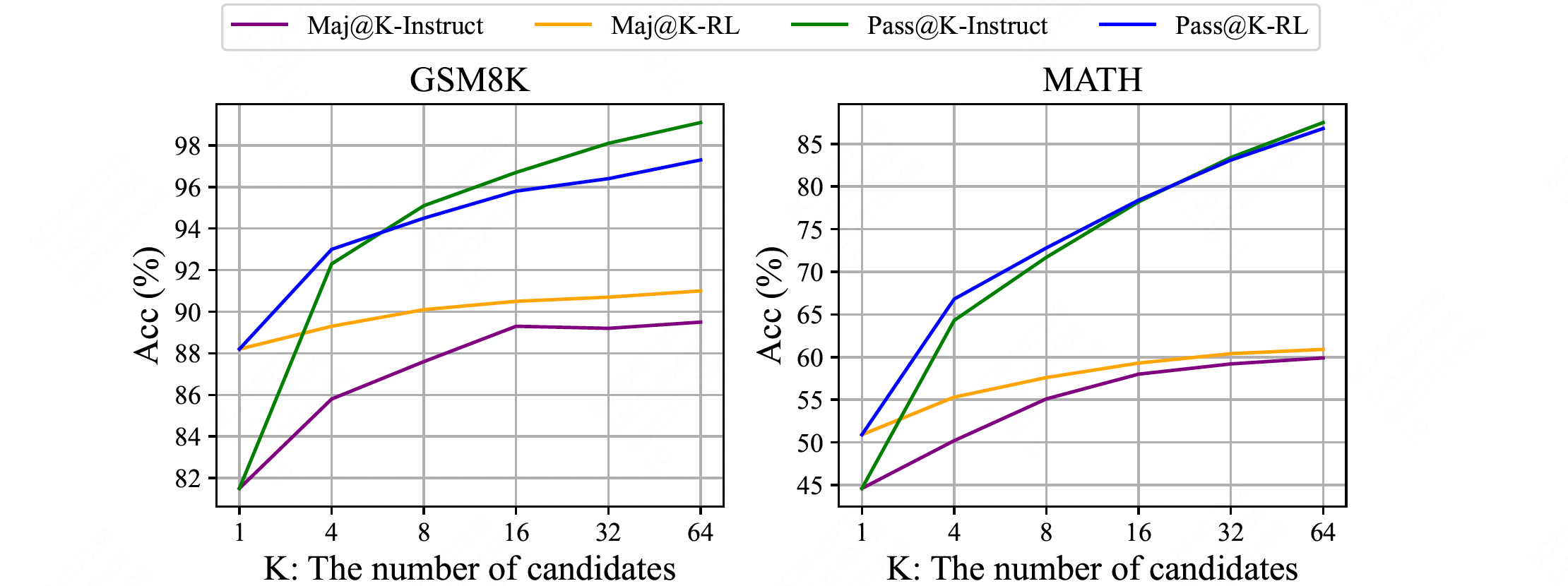
- RL改善的指标是 $\mathrm{Maj} @ \mathrm{~K}$ 而不是 Pass@K,说明RL改善的是 → 模型TopK的结果的能力而不是模型的基础能力。
- [[Reasoning-Decision Alignment]]也是类似的,通过一系列 {{c1 偏好对齐}} 策略来提升模型推理表现。
第二点,如何设计高效的RL算法?
- 数据层面,只用了指令微调阶段的问题然后做采样。#card
- 这这可能也是GRPO值改进 $\mathrm{Maj} @ \mathrm{~K}$ 的原因,未来需要尝试分布之外(out-of-distribution)的问题提示,同时优化采样策略。
- 另外有效的推断技术决定了策略模型的探索效率,也是可能的改进点。
- 算法层面,所有方法都根据奖励信号来进行训练(增加或降低对应的token条件概率),但奖励信号并不总是可靠的,尤其在极端复杂的任务上。#card
- 因此需要探索对奖励信号噪音比较鲁棒的RL算法。
- ds提到像WEAK-TO-STRONG的对齐方法能够有效提升模型的基础能力。
- 奖励函数,ds认为在RL中奖励模型有三个改进方向
- 如何改进奖励模型的 {{c1 泛化}} 能力使得奖励模型能够处理out-of-distribution问题,否则RL只能提升LLM的特定数据分布的能力而不是基础能力
- 如何衡量奖励模型的不确定度,有了不确定度,可以将weak奖励模型提升为 {{c1 weak-to-strong学习算法。}}
- 如何构建 {{c1 细粒度的过程奖励}} 模型,对于一个问题等最后的token输出后判断答案质量是容易的,但对于推断过程中的奖励还不能很好的建模
问题来了:为什么RL是work的,如何设计更有效的RL方法?