OneRec Decoder
- point-wise generation paradigm 点式生成范式
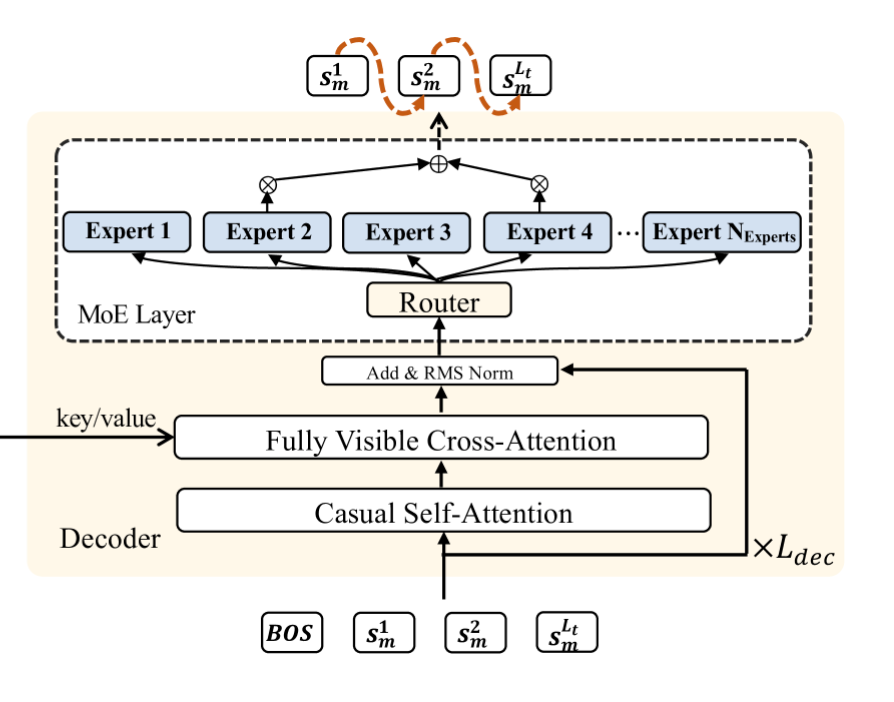
- 解码器输入 #card
- learnable beginning-of-sequence token with the video’s semantic identifiers
- $\mathcal{S}m=\left{s{[\mathrm{BOS}]}, s_m^1, s_m^2, \cdots, s_m^{L_t}\right}$
- $\mathbf{d}_m^{(0)}=$ Emb_lookup $\left(\mathcal{S}_m\right)$
- 通过 Ldec 层 Transformer layer 处理序列 #card

- Mixture of Experts (MoE) feed-forward network #card
- top-k 路由策略
- $\operatorname{MoE}(\mathbf{x})=\sum_{j=1}^k \operatorname{Gate}_j(\mathbf{x}) \cdot \operatorname{Expert}_j(\mathbf{x})$,
- loss-free load balancing strategy
- 训练目标 #card
- NTP 交叉熵损失
- cross-entropy loss for next-token prediction on the semantic identifiers of target video m
- $\mathcal{L}{\mathrm{NTP}}=-\sum{j=1}^{L_t-1} \log P\left(s_m^{j+1} \mid\left[s_{[\mathrm{BOS}]}, s_m^1, s_m^2, \cdots, s_m^j\right]\right)$
OneRec Decoder