OneRec Tokenizer
分词器示意图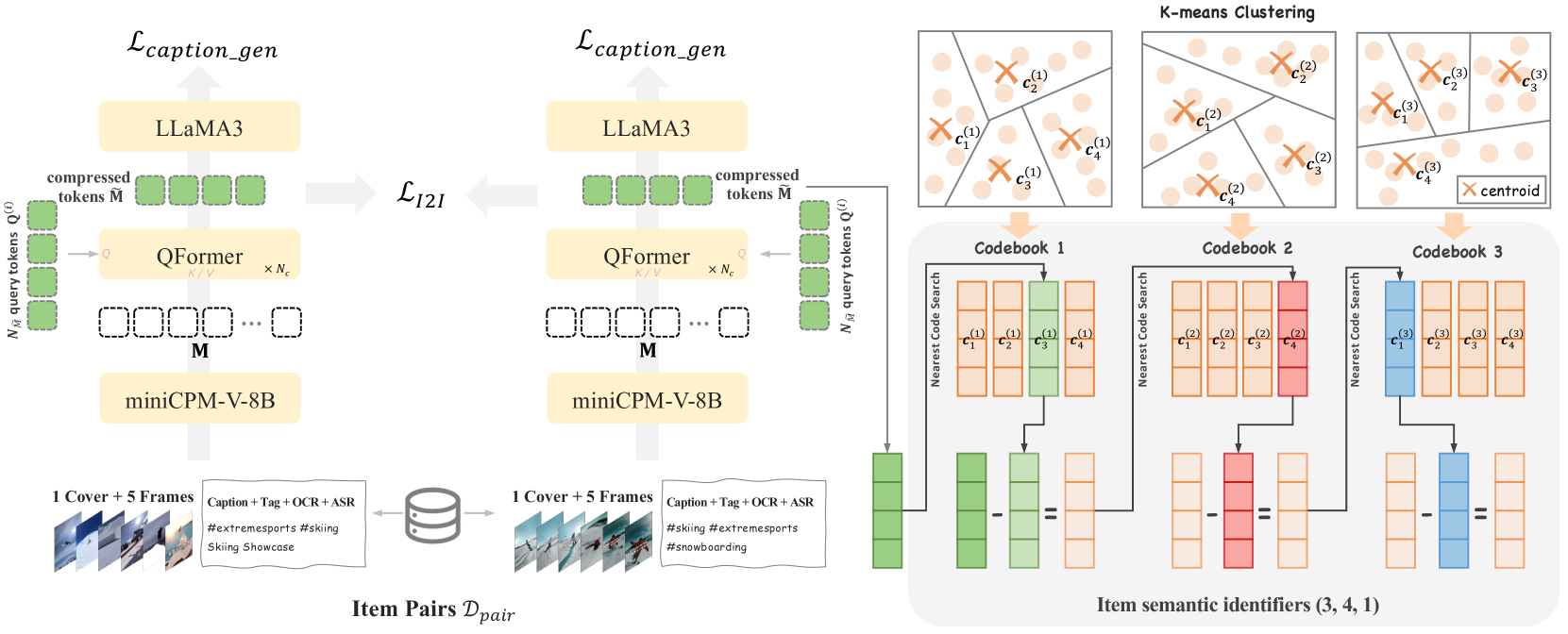
2.1.1 Aligned Collaborative-Aware Multimodal Representation 对齐的协作感知多模态表示
- 视频多模态表示 Multimodal Representations.#card
- 为每个视频引入了多模态输入:字幕、标签、ASR(语音转文本)、OCR(图像转文本)、封面图片以及 5 个均匀采样的帧。
- miniCPM-V-8B 处理生成 $N_M=1280 \text { token vectors } \mathbf{M} \in \mathbb{R}^{N_M \times d_t} \quad\left(d_t=512\right) .$
- 使用 [[QFormer]] 对面的矩阵进行压缩 $N_{\widetilde{M}}=4 \text { learnable query tokens } \mathbf{Q}^{(1)} \in \mathbb{R}^{N_{\widetilde{M}} \times d_t}$
- $$
\begin{aligned}
& \mathbf{Q}^{(i+1)}=\operatorname{Cross} \operatorname{Attn}\left(\mathbf{Q}^{(i)}, \mathbf{M}, \mathbf{M}\right), \
& \mathbf{Q}^{(i+1)}=\operatorname{FFN}\left(\operatorname{RMSNorm}\left(\mathbf{Q}^{(i+1)}\right), \quad \text { for } i \in\left{1,2, \ldots, N_c\right},\right.
\end{aligned}
$$
- $$
- 构建 Item Pair 方法
- User-to-Item Retrieval → 用户最近一次正向点击 item 和用户最近历史正向点击中相似度最高的 item
- Item-to-Item Retrieval → We pair items exhibiting high similarity scores (e.g., the Swing similarity) 相似度高的 item
- Item-to-Item Loss and Caption Loss #card
- item 间 [[contrastive loss]] 对比学习 loss,将相似的 item 表征进行对齐
- 字幕 Caption Loss 使用 [[LLaMA3]] 作为解码器进行下一个词(video captions)预测,保持内容理解能力,减少幻觉
- sim 表示相似函数,tao 代表温度,tk 代表 k-th caption token
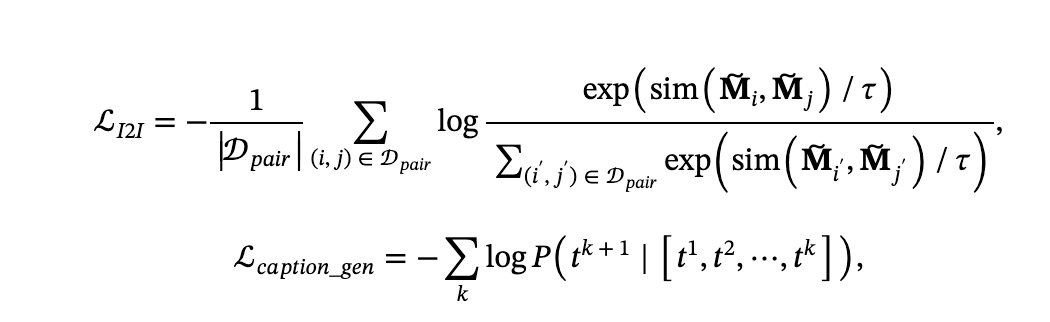
- sim 表示相似函数,tao 代表温度,tk 代表 k-th caption token
2.1.2 Tokenization 分词
- [[RQ-Kmeans]] 在残差上应用 k-means 聚类来构建 codebooks #card
- 三层,找到和输入向量最近接的结果,然后求残差,继续去第二层 codebook 里面找,以此类推。
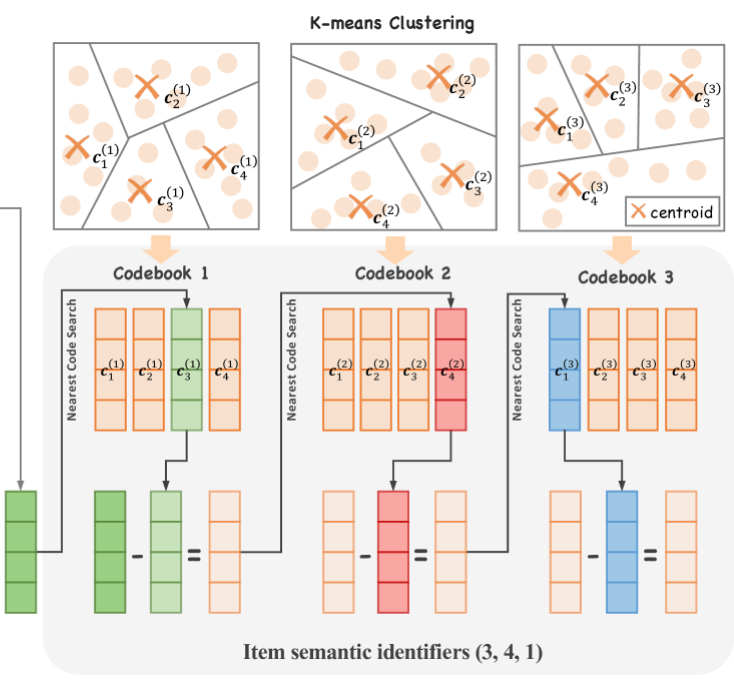
- 三层,找到和输入向量最近接的结果,然后求残差,继续去第二层 codebook 里面找,以此类推。
- [[RQ-Kmeans]] offers enhanced reconstruction quality, better codebook utilization, and improved balance compared to the widely used [[RQ-VAE]] #card
- 重构质量、码本利用率和平衡性方面好
- 最终一个视频被编码成 → Lt coarse-to-fine semantic identifiers $\left{S_m^1, S_m^2, \ldots, S_m^{L_t}\right}$
- which will serve as the output of the OneRec recommendation system, enabling progressive item generation.#card
- 模型生成的输出
- which will serve as the output of the OneRec recommendation system, enabling progressive item generation.#card
OneRec Tokenizer