纠偏长尾物料的实践
物料增强示意 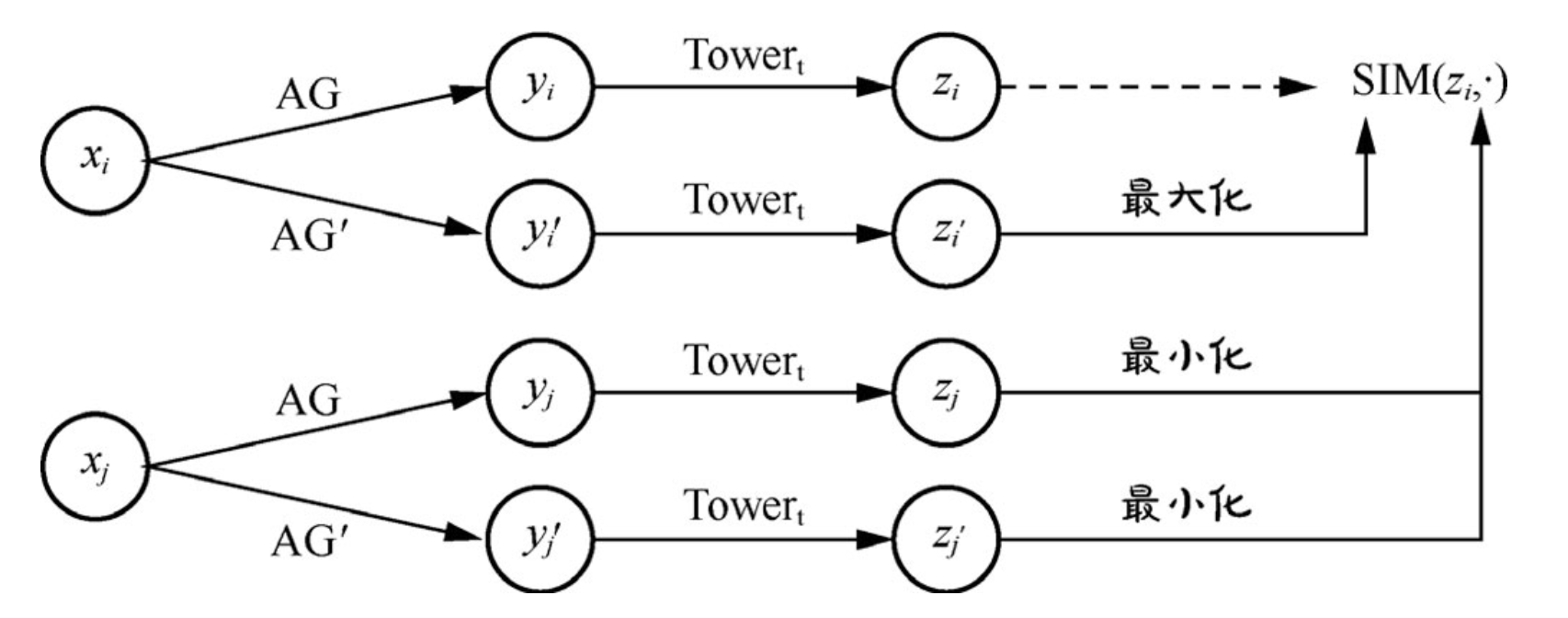
对比学习目标 #card

对比学习要优化的损失不过是向量化召回中常规的[[Sampled Softmax Loss]]#card
$$
\operatorname{Loss}{\mathrm{CL}}=\operatorname{Loss}{\mathrm{CL}}\left(z_i, z_i^{\prime}\right)=-\frac{1}{N} \sum_{i=1}^N \log \frac{\exp \frac{\operatorname{SIM}\left(z_i, z_i^{\prime}\right)}{\tau}}{\sum_{j=1}^N \frac{\operatorname{SIM}\left(z_i, z_j^{\prime}\right)}{\tau}}
$$N 是 batch 大小
$\tau$ 是温度系数,用于平衡调节模型的准确性与扩展性
针对物料特征的两个增强转化函数AG和AG’
+

+ 随机特征遮蔽(Random Feature Masking,RFM)#card
+ a 将一个物料的所有Field随机拆分到两个变体中去。
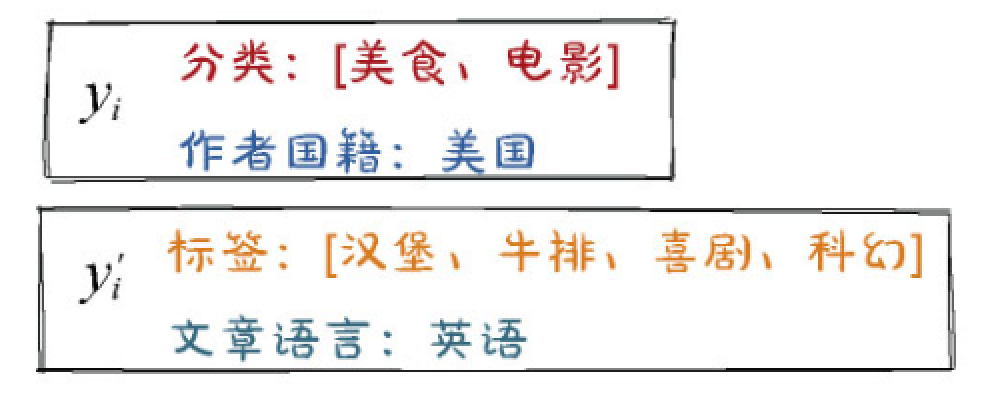
+ #card 关联特征遮蔽(Correlated Feature Masking,CFM)
+ 将一个物料的所有Field拆分到两个变体中,但不再是随机拆分,而是将强关联的Field拆分到一起。
+ 如图8-13(b)所示,“分类”与“标签”都是描述文章内容的,都拆分到变体[插图]中;“作者国籍”和“文章语言”与作者属性强相关,都拆分到变体[插图]中。
+ 至于各Field之间的关联程度如何衡量,可以人工指定,也可以通过计算“互信息”提前准备好。
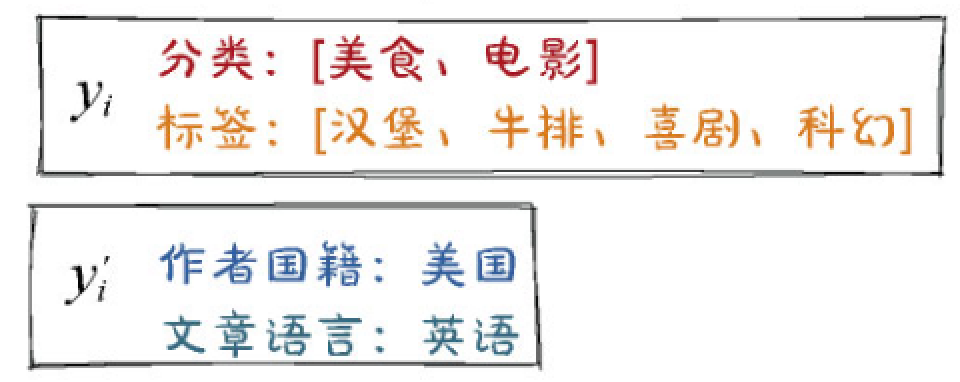
+ #card 随机丢失(Dropout):
+ 不再拆分Field,而是将一些多值Field(比如分类、标签)中的特征值随机拆分到两个变体中

样本策略
- 主任务的训练样本与对比学习任务的训练样本应该来自不同的分布,这一点对模型效果至关重要。#card
训练主任务时,正负样本都来自曝光数据,其中以老物料为主。
训练对比学习的辅助任务时,物料是从所有候选物料中平均抽样产生,小众物料、新物料占比较主任务有大幅提升。原因前边已经分析过,对比学习的目标是放大少数群体的效应,样本策略自然应该向鲜有曝光的小众物料倾斜。
对比学习辅助双塔模型
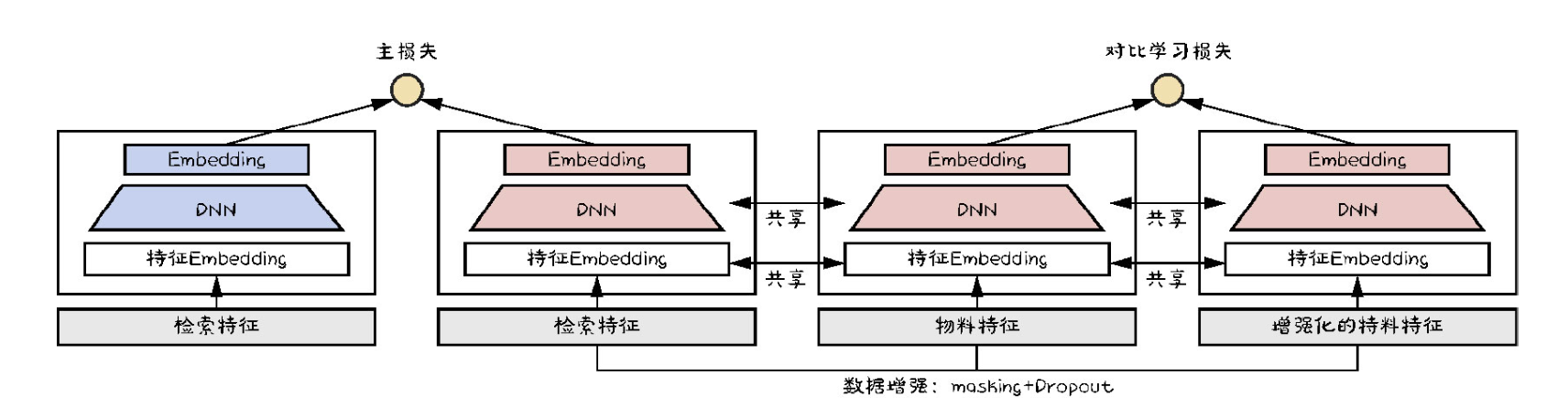
+ 物料塔、物料特征的Embedding这些参数是被主辅任务共享的,唯有如此,才能达到 **纠偏** 的目的。