面向相关性的向量召回优化
文本向量表征的模型(函数)不同的结构
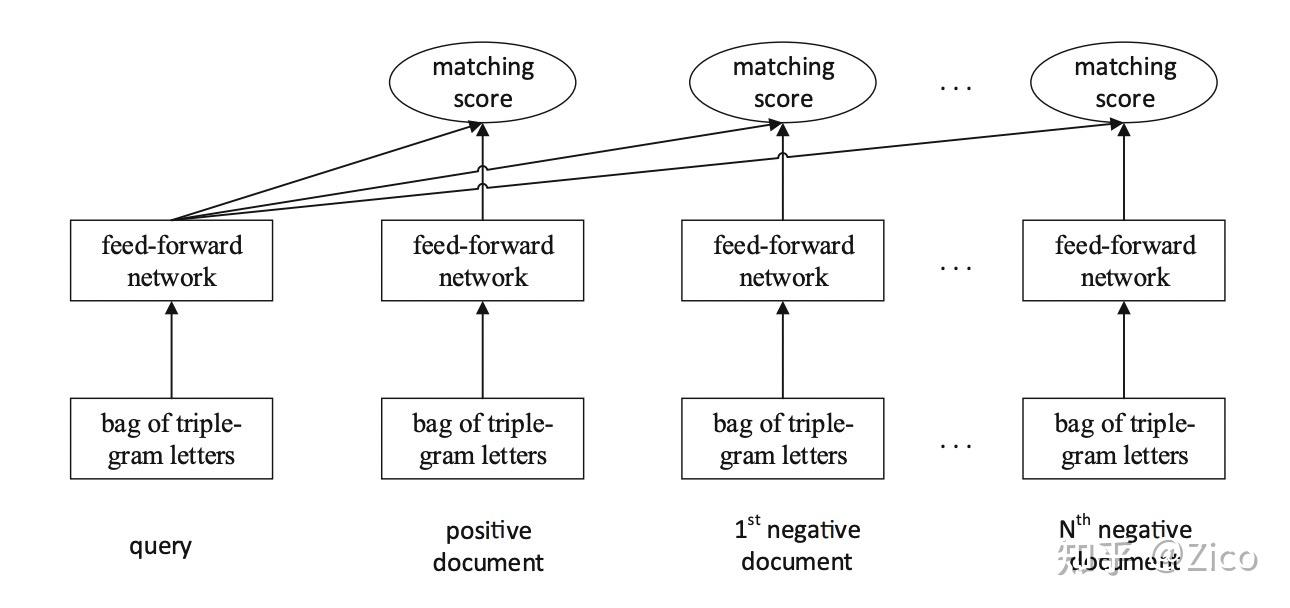
- DSSM 全连接网络表征 #card
输入的query和doc首先用词哈希的方法被表示成triple-gram的词袋向量(multi-hot向量,向量大小为词典大小,词出现的位置为1,没出现的位置为0)。
而后接入多层全连接网络,全连接输出query和doc的语义表征向量,并使用cosine相似度来度量二者的匹配分。
最后通过最小化Loss(Pairwise loss、Triple loss、InfoNCE等)使得query和doc的正样本对距离近,负样本对距离相对远
基于卷积网络
- CDSSM [2]使用滑动窗口来提取模型输入的n-gram信息,如滑动窗口为3的时候,对每个词都会提取出一个triple-gram表示向量(multi-hot向量),并将所有词的向量拼接得到整个句子的特征输入。#card
- 而后再经过多层常规的卷积和池化操作,分别得到query和doc的语义表示向量,进而优化正负样本对的距离远近。
- CDSSM [2]使用滑动窗口来提取模型输入的n-gram信息,如滑动窗口为3的时候,对每个词都会提取出一个triple-gram表示向量(multi-hot向量),并将所有词的向量拼接得到整个句子的特征输入。#card
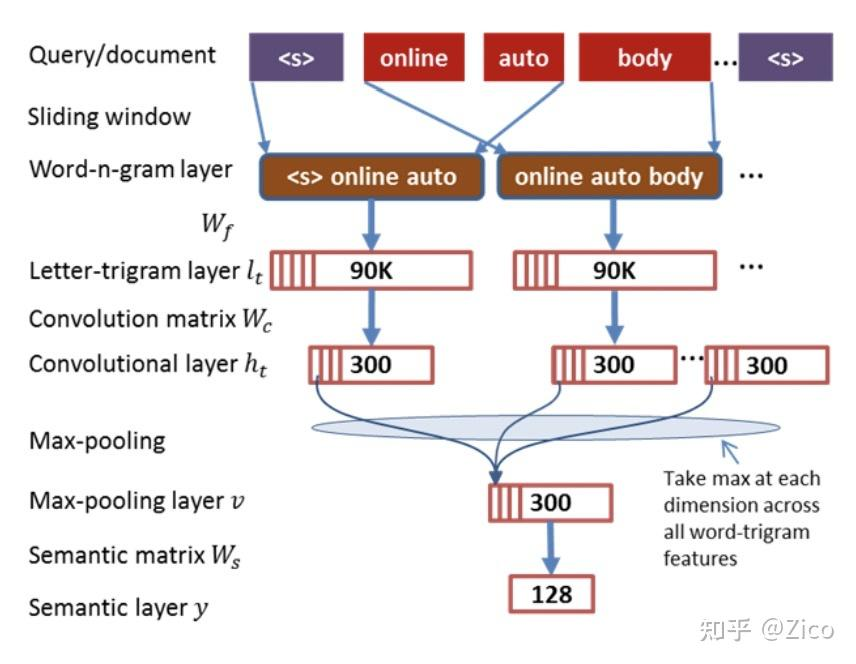
+ 在word embedding技术流行之后,基于卷积的DSSM往往会先将各个词映射成embedding 矩阵,进而对embedding矩阵做多核的卷积池化操作,进一步提升了文本表征的效果 #card
基于循环神经网络
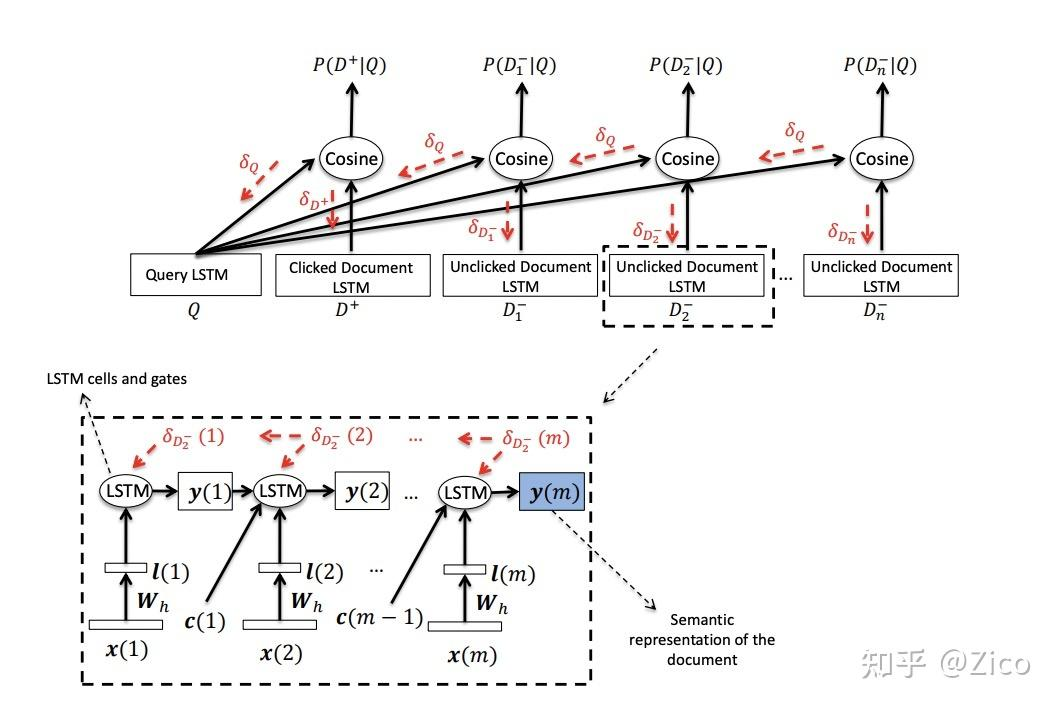
- LSTM-DSSM[4]。其结构与经典的DSSM一致,不同在于使用LSTM为encoder提取输入的文本特征。 #card
基于BERT
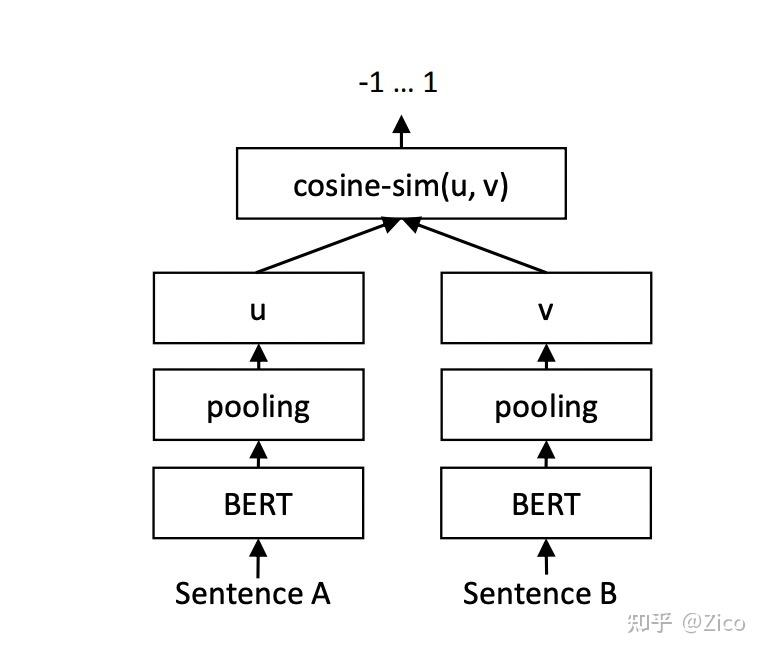
- Sentence-BERT #card
特征
特征增强#card
特征或者数据的增强可以在数据有限的情况下,通过一些简单的变换操作起到变相扩充样本的作用,进而提升文本特征输入的丰富度。同样,即使有足够的数据,特征/数据增强很多时候也能进一步提升模型的鲁棒性。
[[NLP 数据增强方法]]
特征融合可以分为两条思路:
特征内部:#card
- 通过字、词、短语多粒度特征分别建模,而后进行融合来增加特征的丰富度;也可通过字、词、短语分层表示的方式融合多粒度的特征,如ELMO[8]是典型的考虑上下文特征的字、词、短语层级表示结构。
补充特征:#card
- 除了基础文本特征外,电商场景下有十分的方式补充特征,如融入电商知识(query和商品类目、属性关系等信息);通过行为数据挖掘相同语义的query,对当前query进行信息补充,以缓解短文本信息不足的问题等等。
多模态特征
数据
- 参考 ### 训练数据