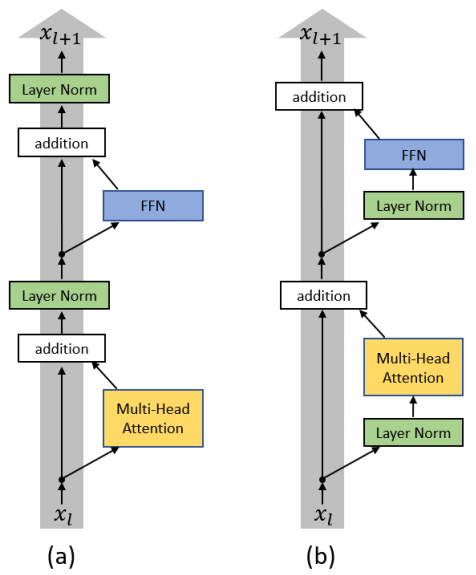
- [[Pre Norm]] ↔ $x_{n+1}=x_{n}+f\left(\operatorname{norm}\left(x_{n}\right)\right)$
- 第二项的方差由于有 norm 不会随层数变化,x 的方差在主干上随层数累积。到达深层后,单层对主干的影响很小,不同层在统计上类似。
- $x_{n+2}=x_{n+1}+f\left(\operatorname{norm}\left(x_{n+1}\right)\right)=x_{n}+f\left(\operatorname{norm}\left(x_{n}\right)\right)+f\left(\operatorname{norm}\left(x_{n+1}\right)\right) \approx x_{n}+2 f\left(\operatorname{norm}\left(x_{n}\right)\right)$
- 这样训练的深层模型更像是扩展模型宽度,相对好训练。
- [[Post Norm]] ↔ $x_{n+1}=\operatorname{norm}\left(x_{n}+f\left(x_{n}\right)\right)$
pre 和 post 具体含义 #card
- 先 norm 再残差 ((66b0ee62-baeb-492d-8af8-0a3e7ea3d02f))
- 先残差再 norm ((66b0ee62-8a5e-439c-85f6-5d2245ca5c2b))
[[DeepNet]]