双塔模型样本选择
正样本
少部分物品占据大部分点击,导致正样本 大多是热门物品
- 解决方案 :-> 过采样冷门物品,或降采样热门物品
- 过采样(up-sampling) :-> 一个样本出现多次
- 降采样(down-sampling) :-> 一些样本被抛弃
- 解决方案 :-> 过采样冷门物品,或降采样热门物品
为什么需要对负样本进行采样 ? #card
未召回样本数量太多,需要进行采样。
item 特征包括:id 和 meta 特征
- 维护全量样本的列表进行负采样内存成本高,无法接受
[[负样本]] 选择方法
如何选择困难负样本 #card

简单负样本:[[batch 内负采样]]
in-batch 采样 #card
实现方法:batch 内其他用户的正样本做为当前用户的负样本
特点:需要 batch_size 比较大
in-batch 采样 + bias 校正 #card
batch 内得到的负样本,可能热门物品被当成负样本的概率变大,造成对热门商品的惩罚过高
通过引入频率修正
Xinyang Yi et al. Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations. In RecSys, 2019.

+ 混合采样 #card
+ Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations
+ Cross-Batch Negative Sampling for Training Two-Tower Recommenders
业务向 hard mining 方法
- [[@Real-time Personalization using Embeddings for Search Ranking at Airbnb]]
- 增加 “与正样本同城的房间” 作为负样本,增强了 正负样本在地域上的相似性;
- 增加 “被房主拒绝” 作为负样本,增强了正负样本 在“匹配用户兴趣爱好”上的相似性
- [[@Embedding-based Retrieval in Facebook Search]]
online#card
在线一般是batch内其他用户的正例当作负例池随机采,
本文提到选相似度打分最高的作为hard样本,
同时强调了最多不能超过两个hard样本。
offline
- 在线batch内池子太小了不一定能选出来很好的hard样本,离线则可以从全量候选里选。#card
具体做法是对每个query的top-k结果利用hard selection strategy找到hard样本加入训练,然后重复整个过程。
这里提到要从101-500中采,太靠前的也许根本不是hard负例,压根就是个正例。
以及两个很好的经验,
第一个是样本easy:hard=100:1,
第二个是先训练easy再训练hard效果<先hard后easy
- 在线batch内池子太小了不一定能选出来很好的hard样本,离线则可以从全量候选里选。#card
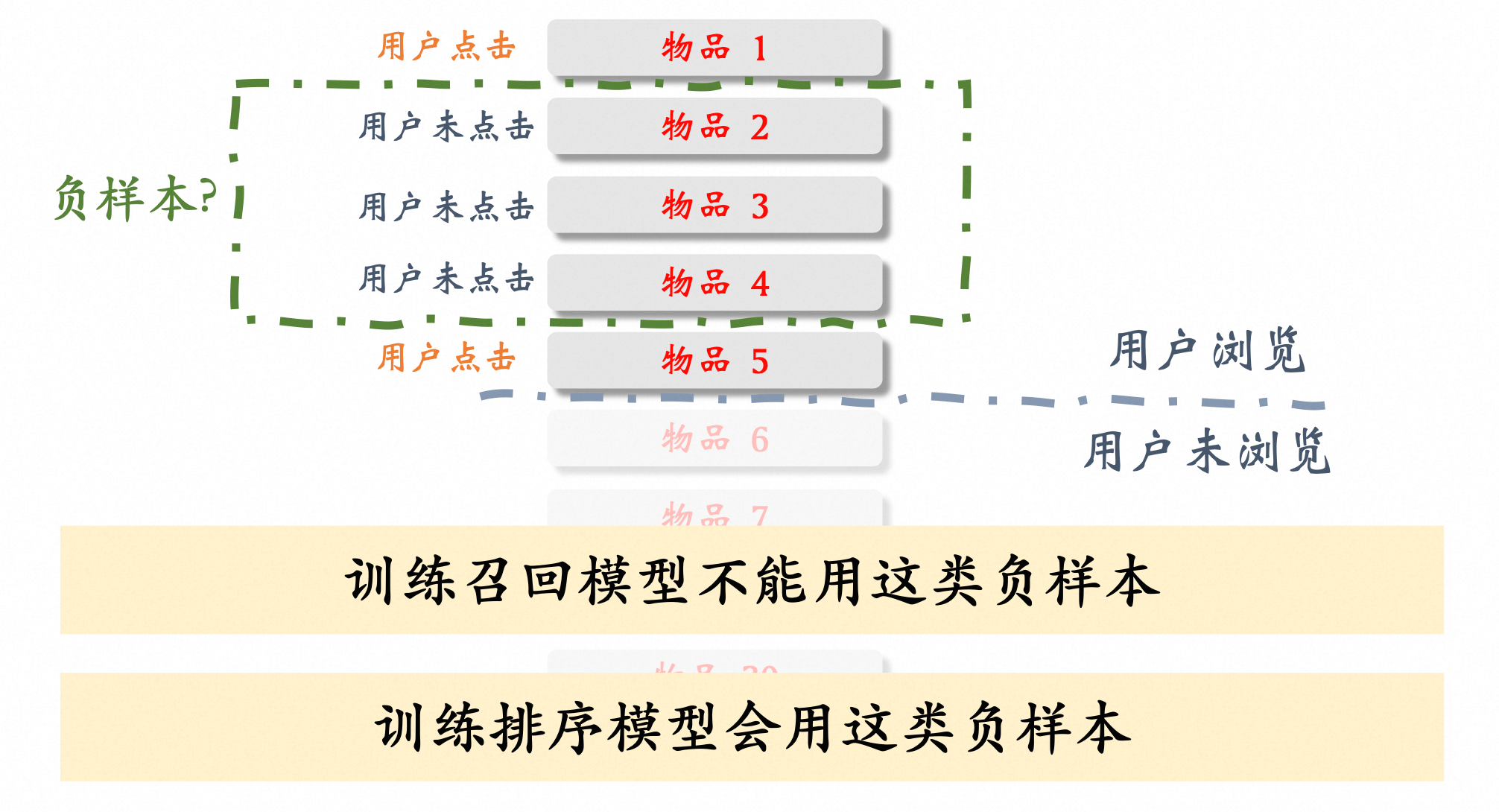
为什么曝光但是没有点击不能做为召回的负样本 #card