特征交叉
自动高阶特征交叉效果一定好吗? #card
信息表达能力强,但是模型复杂度高,导致模型学习难度增加。
过拟合,
手动交叉特征,效果非常明显。
主要工作
人工设计交叉特征
[[Linear Regression]]
- 原始 LR 没有非线性能力,无法建模非线性关系
[[POLY2]] 人工构造二阶特征加入 LR 模型,提升模型的表达能力
- $POLY2(w,x)=\sum^n_{j_1=1}\sum^n_{j_2=j_1+1}w_{h(j_1,j_2)}x_{j_1}x_{j_2}$
自动学习交叉特征
- [[GBDT+LR]]
DNN 隐式建模 bit-wise 特征交叉
隐式和显示
隐式交叉:类似于MLP通过非线性函数期望学习到交叉项的模型被称为隐式交叉 #card
- 隐式交叉被认为既不确定能否学到也不确定学到了哪种交叉项,并且缺乏可解释性。
显示交叉:使用 内积,外积,元素积等操作模拟交叉项 的模型
Bit-Wise和Vector-Wise
Bit-Wise:特征域内部也进行交叉,例如性别的Embedding为8维,对于这8个比特也进行交叉,即自身与自身做交叉,不过这些比特的物理意义已经很不明显了,将其再做交叉是否有意义有点存疑。#card
- 代表性的模型为[[Deep Crossing]], [[DCN]] ,将所有特征Embedding Concat到一起后再做外积,即拼接后的大Embedding的比特分量两两相乘。
Vector-Wise、Field-wid:只在特征域之间进行交叉,比较符合物理意义,例如用户性别 x 商品类目,用户职业 x 新闻主题,代表性的模型为[[xDeepFM]]。#card
每个特征学习 embedding 向量,多个特征间特征交叉通过 embedding 向量计算
该类方法需要交叉的特征维度对齐,但是一般我们会为不同的特征设置相对合理的维度,此时为了进行Vector-Wise交叉,可以使用映射矩阵强行拉齐。
[[FFM]] 为每个特征学习 f 个 embedding
串行和并行
- 串行交叉:交叉网络层与全连接层堆叠在一起,即在表征学习的过程中也进行交叉,例如 [[PNN]] 等。#card
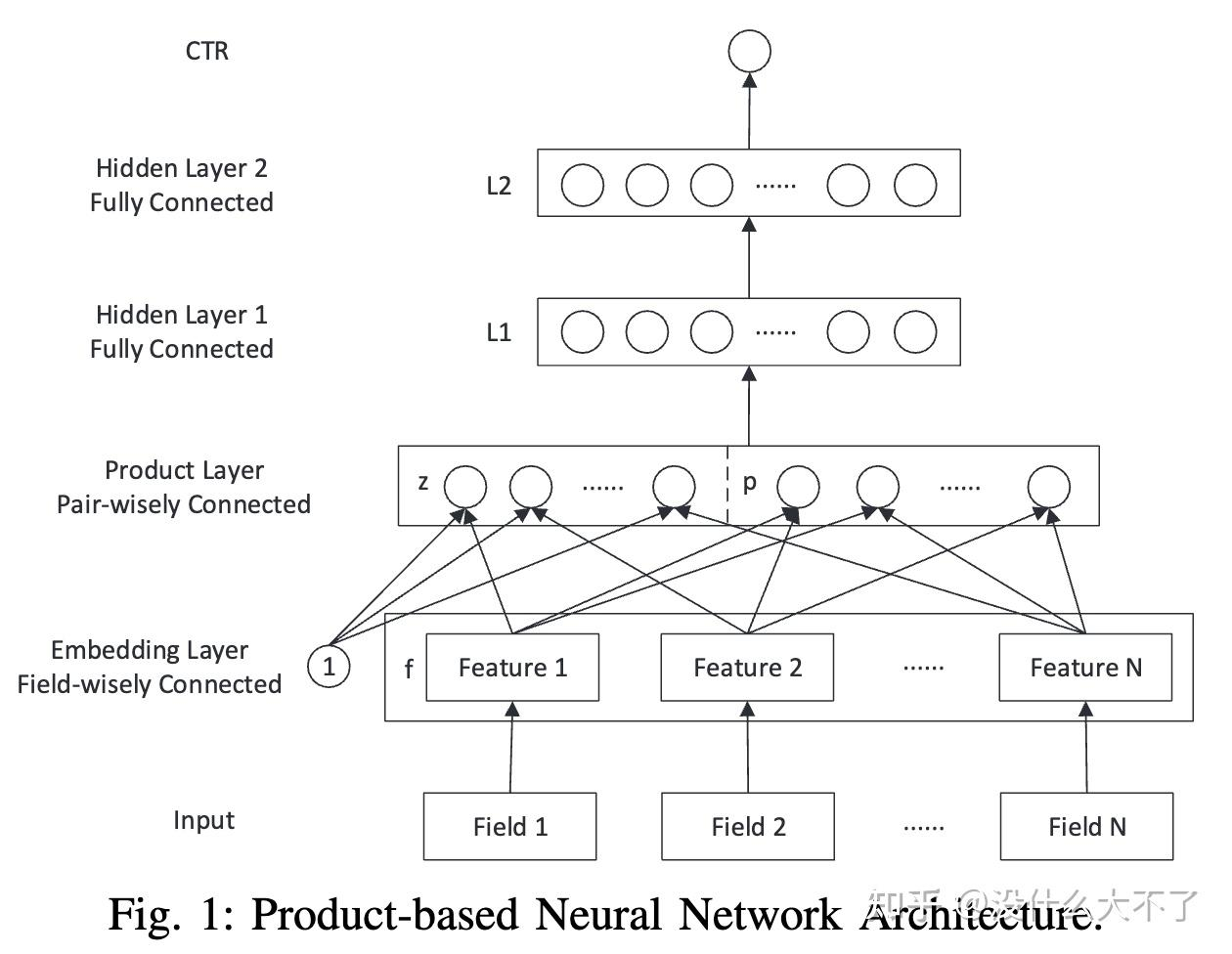
+ 并行交叉: **交叉网络层单独作为一列,即双塔结构两者互不干扰** ,例如DeepCross,xDeepFM等。
共享与解耦
- 共享参数:交叉的特征 Embedding 底层是共享的,参数共享有利于模型泛化到稀疏特征,但是也会破坏对交叉特征的记忆性,即所谓样本穿越[6]。
- 解耦参数:与共享相反,交叉的特征 Embedding 参数是独立的,有利于记忆性,但是会导致Embedding层的参数量膨胀,代表性的工作[[CAN]]在两者之间进行了折中。
x2i与i2i
x2i交叉:user,query与target item的交叉,例如 #card
user/query x item cate/seller/brand近30天的pv/ipv/pay,是比较常见的一类交叉模式。
特别地,相似推荐中,已点击item与待推荐item之间的交叉。
i2i交叉:sequence item与target item的交叉,是对行为序列兴趣建模的一种强化。
在召回阶段往往会有一路 [[i2i 召回]] ,即以用户历史行为过的item作为trigger召回一些用户可能感兴趣的item,代表性的方法为[[swing]]等,其召回的是 :-> 一些共现强度较高的item。
基于Transformer等序列模型对行为序列特征进行抽取是排序模型中一个重要的模块,代表性的方法为DIN,其使用待推荐的广告商品作为Q计算行为序列中商品的Attention分布,进一步我们可以使用Transformer模型,详情可以参考[[@浅谈行为序列建模]]
多头注意力学习到了哪些含义的Attention分布?
最直观的是相似强度,例如#card
- 与target item同属于一个类目,品牌或卖家的sequence item,这些商品在相似语义空间会被赋予较大的权重。
另一类是关注强度,#card
- 这里是指模型通过点击次数,购买次数,停留时间,与当前时间差等行为的context特征学习到的用户对该行为过的商品的关注程度,显然行为次数越多,停留时间越长,距当前越靠近说明用户更关注该商品。
还有一类容易被忽视的是共现强度,例如耳熟能详的“啤酒奶粉”,目前的行为序列建模能够学习到共现强度吗,
理论上是可以的,分为两个阶段:#card
1)Attention模块中的一个注意力头挑选出行为序列中共现强度高的item,例如共现更多的seq item与target item的点积距离更近,类比FM我们认为这是理论上可行的。最终的序列Embedding中融合了共现item的信息。
2)MLP继续将得到的序列Embedding与target item做交叉从而学习到seq i 2 target i共现。
但是存在着两点阻碍:#card
1)相比FM Attention模块离最终目标还是太远,中间隔了一个MLP,梯度回传不一定能使模型通过点积学习到共现。
2)喂入MLP的特征往往太多了,实际业务场景中往往多达上千个特征,想要MLP学习到seq i 2 target i不容易,很容易被其他众多特征所淹没。
针对以上两个问题我们可以做出相应改进,在目前的场景经过实验也是行之有效的:#card
离线统计i2i交叉特征并作为行为序列的context特征,帮助模型更快速更直接学习到i2i共现强度,从而挑出那些共现更多的item。
使用一个小的专门的交叉网络来学习seq i 2 target i,避免这两个特征被淹没在其他众多特征中。例如,如果使用的是transformer模块,我们可以直接将FNN改造为小交叉网络,将sequence emb与target item emb concat后输入FNN。