有偏估计与[[无偏估计]]
- 样本方差与整体方差相等时是无偏估计,样本方差分母是 n-1 为了追求无偏估计
计算总体的均值和方差时,拿到的数据是对总体的采样,因此计算出的方差比总体方差小$\frac{\sigma^2}{n}$。
自协方差
[[自相关]]系数 ACF
偏自相关系数 [[PACF]]
离散情况下:结果乘以结果概率的总和
连续 $$E(x) = \int xf(x)dx$$
作用:衡量 {{c1 两个分布之间的距离}}
为什么不对称 → 计算两个分布之间的不同,从分布 A 的角度看分布 B 的相似程度
特点
一个分布相比于另外一个分布的信息损失。
$$D_{K L}(A | B)=\sum_{i} P_{A}\left(x_{i}\right) \log \left(\frac{P_{A}\left(x_{i}\right)}{P_{B}\left(x_{i}\right)}\right)=\sum_{i} P_{A}\left(x_{i}\right) \log \left(P_{A}\left(x_{i}\right)\right)-P_{A}\left(x_{i}\right) \log \left(P_{B}\left(x_{i}\right)\right)$$
A和B的交叉熵 = A与B的KL散度 - A的熵。
机器学习模型学到的分布和真实数据的分布越接近越好,但是现实中只能让模型学到的分布和训练数据的分布尽量相同,即 KL 散度最小。
P 真实样本的分布,Q模型预测样本的分布,如果 Q 越接近 P,散度就越小。散度的值非负。
标准变换
选择 $\lambda$ 使得变换后的样本正态性最好
+
常用 $\lambda$ 值,$y(\lambda)= y_i^{\lambda}$
任意一个函数表示成诺干个正交函数的线性组合。
时域 空间域
频域 变换域
((6357f72c-7135-48f3-891f-702ce0de3603))
$F(\omega)=\int_{-\infty}^{+\infty} f(t) \cdot e^{-i \omega t} \mathrm{~d} t$
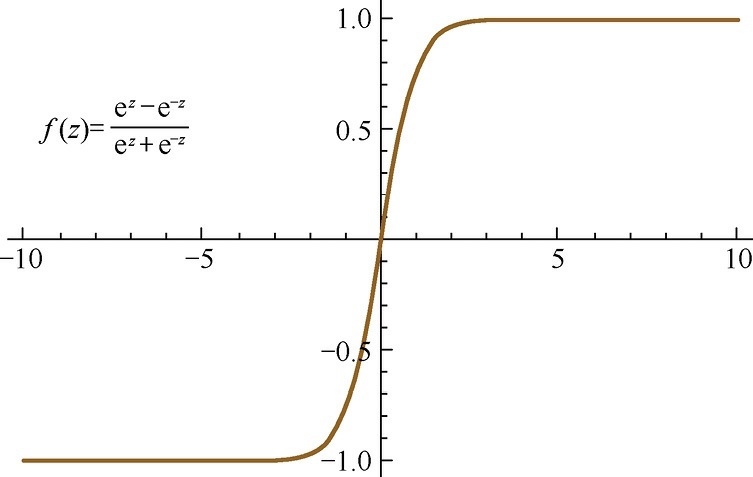
欧拉公式
使用正弦曲线做为基,会考虑整个坐标轴情况
$f(x)=p^x(1-p)^{1-x}$
$E(x)=xf(x)= 0 * (1-p) + p= p$
$D(x)=p(1-p)$
抛一次硬币
求解唯一的参数 $\mu$ 或 $p$
样本的均值是伯努利分布的[[充分统计量]] ((654a59d8-acbd-438e-8a0d-95513dfe832c))(分布的参数 $\mu$ 可以由该统计量估计得到)
缩写 → ACF
1 | # https://github.com/Arturus/kaggle-web-traffic/blob/master/make_features.py#L88 |
$$R_{k}=\frac{\sum_{i=1}^{n-k}\left(X_{i}-\bar{X}\right)\left(X_{i+k}-\bar{X}\right)}{\sum_{i=1}^{n}\left(X_{i}-\bar{X}\right)^{2}}$$
0:L-1-t 和 子序列 t:L-1 的相关性是最大的Ref
[[MAP]] 公式 → ${\log P(x,w)P(w) = \log P(x,w) + \log P(w)}$
[[Bayesian]]概率:概率很难求,求反概率就很容易。
$P(\theta|X) = \frac{P(X|\theta)P(\theta)}{P(X)}$
[[极大似然估计]]
[[最大后验估计]]
贝叶斯估计
+
一个随机变量的对数服从 [[正态分布]],则该随机变量服从对数正态分布。
$\ln (Y) \sim N\left(\mu, \sigma^2\right)$
[[概率密度函数]]
期望
方差
衡量两个随机变量 {{c1 各个维度偏离其均值的程度}}
协方差矩阵表示方式 #card
[[Ref]]
标准变换
选择 $\lambda$ 使得变换后的样本正态性最好
+
常用 $\lambda$ 值,$y(\lambda)= y_i^{\lambda}$
$\lambda = 2, y(\lambda)= y_i^2$
$\lambda = 0.5, y(\lambda)= \sqrt {y_i}$
$\lambda = -0.5, y(\lambda)= \frac{1}{\sqrt {y_i}}$
$\lambda = -1, y(\lambda)= \frac{1}{y_i}$
自协方差
信号与其经过时间平移的信号之间的[[协方差]]
$r(k)=\frac{1}{n} \Sigma_{t=k+1}^n\left(Z_t-\bar{Z}\right)\left(Z_{t-k}-\bar{Z}\right)$
[[自相关]]系数 ACF
$A C F(k)=\Sigma_{t=k+1}^n \frac{\left(Z_t-\bar{Z}\right)\left(Z_{t-k}-\bar{Z}\right)}{\Sigma_{t=1}^n\left(Z_t-\bar{Z}\right)^2}$
衡量信号其自身在不同时间点的相关度
找出重复模式或识别隐含在谐波频率中小时的基频
偏自相关系数 [[PACF]]
自相关衡量想要衡量 z(t) 和 z(t-k) 的相关关系,实际上 z(t) 还会受到 z(t-1) 到 z(t-k-1) 的影响。
PACF 单纯测量 z(t-k) 对 z(t) 的影响
偏相关
PACF 和 ACF 区别
ACF 一个期望,用整个时间序列的期望
PACF 两个期望,两个序列用各自序列的期望