李宏毅强化学习课程笔记 Actor Critic
我的笔记汇总:
- Policy Gradient、PPO: Proximal Policy Optimization、Q-Learning
- Actor Critic
- Sparse Reward
- Imitation Learning
Actor Critic
policy gradient
- 给定在某个 state 采取某个 action 的概率。
- baseline b 的作用是保证 reward 大的样本有更大的概率被采样到。
- 从当前时间点累加 reward,并且当前 action 对后面的 reward 影响很小,添加折扣系数。
- PG 效果受到采样数量和质量影响。

Q-learning
状态价值函数 $V^{\pi}(s)$
状态行动价值函数 $Q^{\pi}(s,a)$
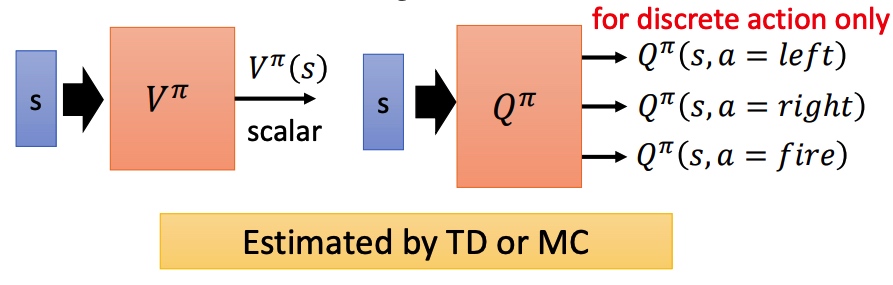
Actor-Critic
用 V 和 Q 替换 PG 中的累积 reward 和 baseline。新的模型需要训练两个网络,比较困难。
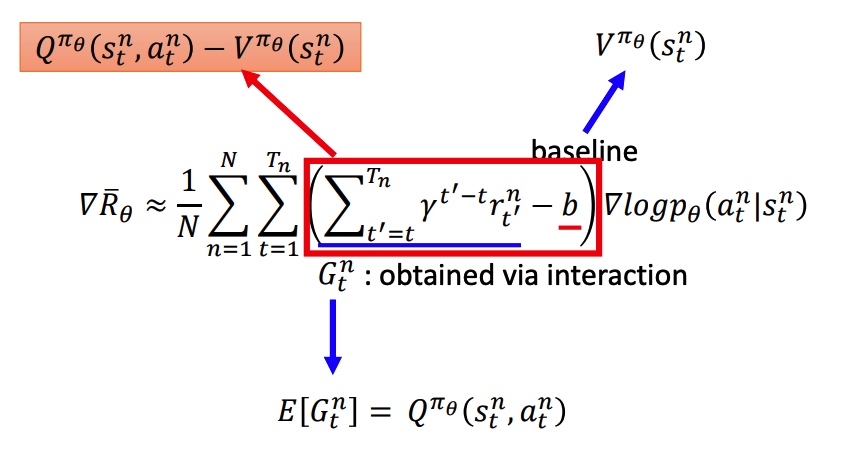
Advantage Actor-Critic
用 V 去替代 Q,能降低模型整体方差(MC 到 TD)。最下面两个公式转化是由实验得到。

训练过程:
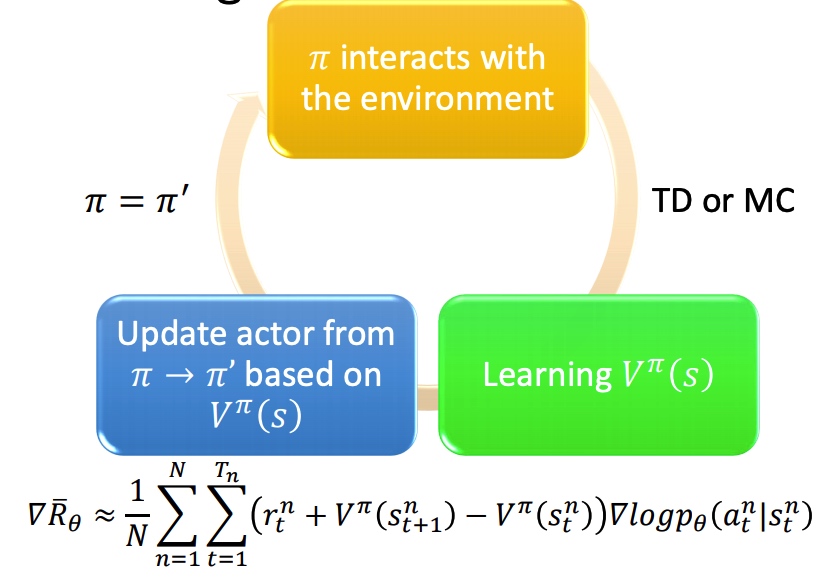
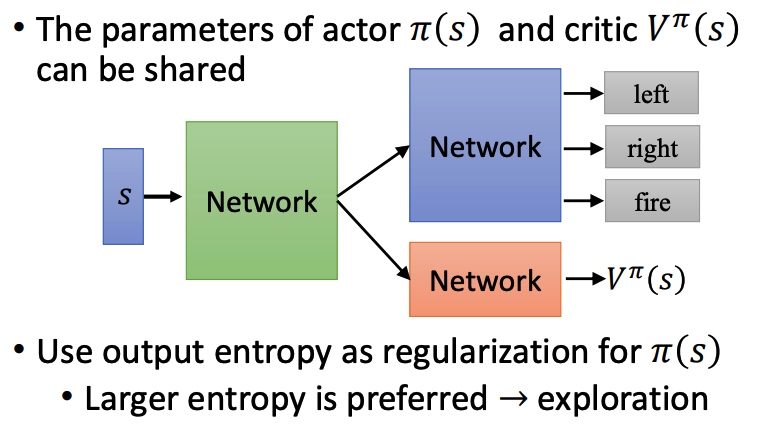
tip:
- actor 和 critic 具有相同的输入 s,可以共享部分网络结构。
- output entropy 作为 pi 的正则项,entropy 越大采样效果越好。
Asynchronous Advantage Acotr-Critic A3C
- 利用多个 worker 去训练。
- 每个 worker 复制主模型的参数。
- 每个模型单独采样,并且计算梯度。
- 更新全局参数。
Pathwise derivative policy gradient
该网络不仅仅告诉 actor 某一个 action 的好坏,还告诉 actor 应该返回哪一个 action。

将这个 actor 返回的 action 和 state 一起输入到一个固定的 Q,利用梯度上升更新 actor。
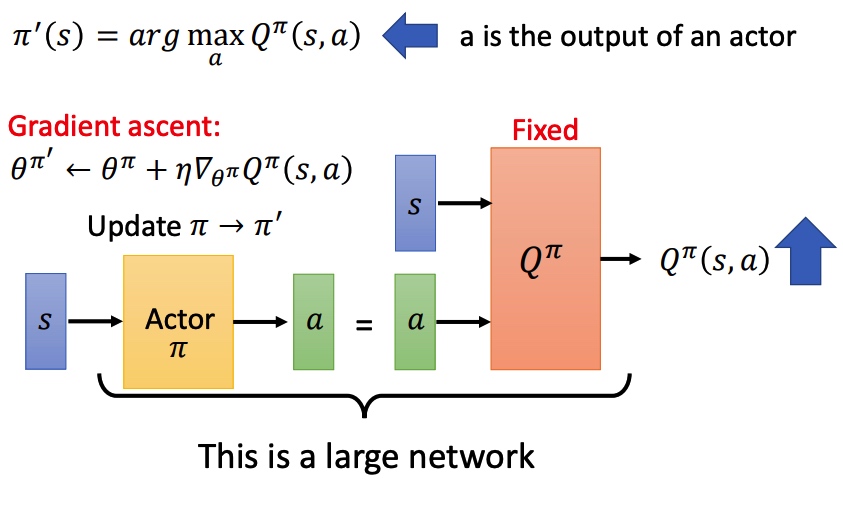
完整的训练过程和 conditional GAN 类似, actor 是 generator,Q 是 discriminator。
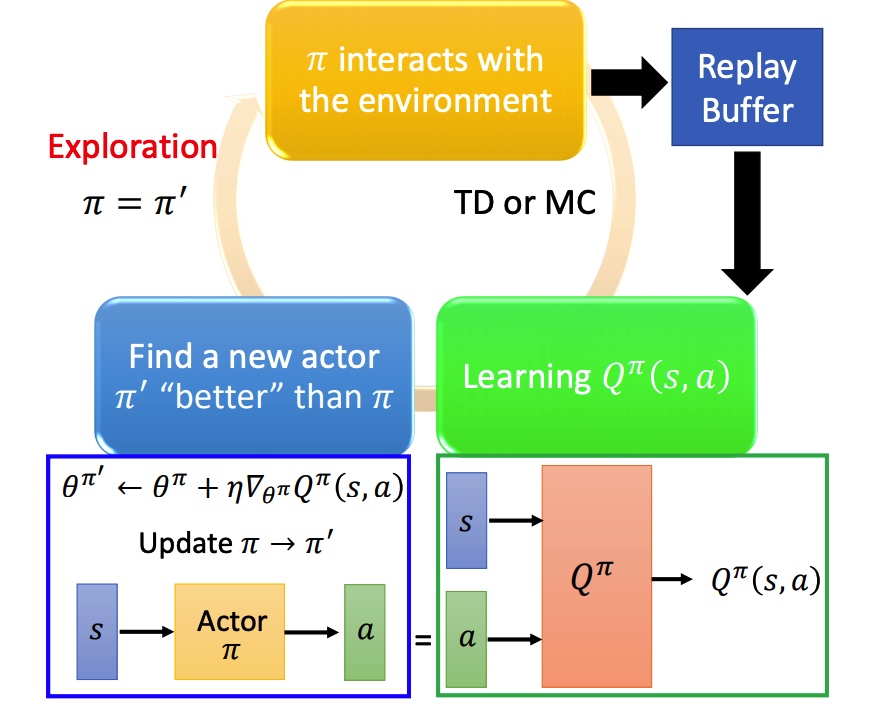
算法:
- action 由训练的 actor 决定
- 利用 s 和 a 更新 Q

GAN 和 AC 方法对比

李宏毅强化学习课程笔记 Actor Critic
https://blog.xiang578.com/post/reinforce-learnning-basic-actor-critic.html