李宏毅强化学习课程笔记 Imitation Learning
我的笔记汇总:
- Policy Gradient、PPO: Proximal Policy Optimization、Q-Learning
- Actor Critic
- Sparse Reward
- Imitation Learning
apprenticeship learning
- 无法从环境中获得 reward。
- 某些任务中很难定义 reward。
- 人为设计的奖励可能导致意外的行为。
学习专家的行为。
Behavior Cloning
监督学习,但是样本有限。
Dataset Aggregation
- 通过行为克隆得到 actor $\pi_1$
- 利用 $\pi_1$ 和环境交互得到一些新的样本
- 由专家对上一步采样得到的样本进行标注
- 利用新得到的样本训练 $\pi_2$
如果机器的学习能力有限,可能复制专家多余无用的动作。监督学习无法区分哪些是需要学习、哪些是需要忽视的行为。
Miss match
监督学习中,我们假设训练数据和测试数据有相同的分布。Behavior Cloning 中可能分布不同。

Inverse Reinfofcement Learning
反向强化学习
没有 reward 函数,通过专家和环境互动学到一个 reward function,然后再训练 actor。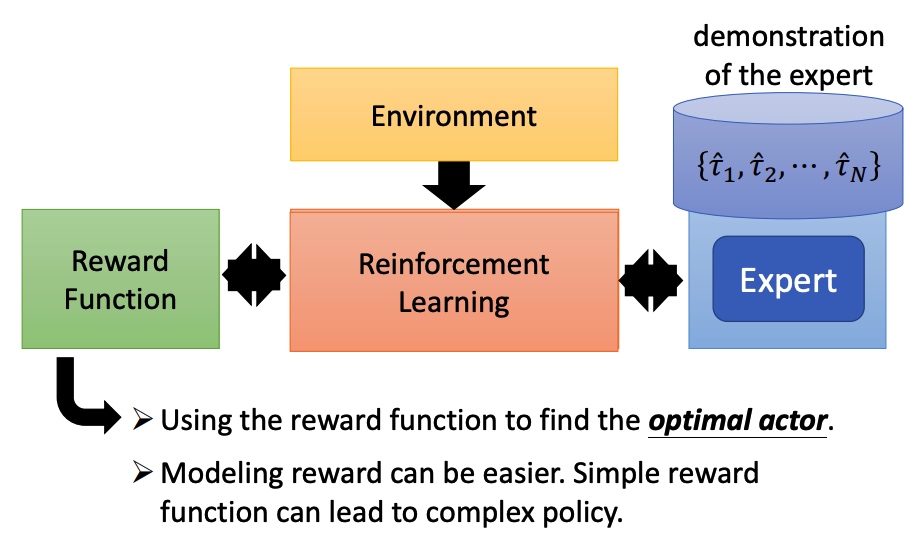
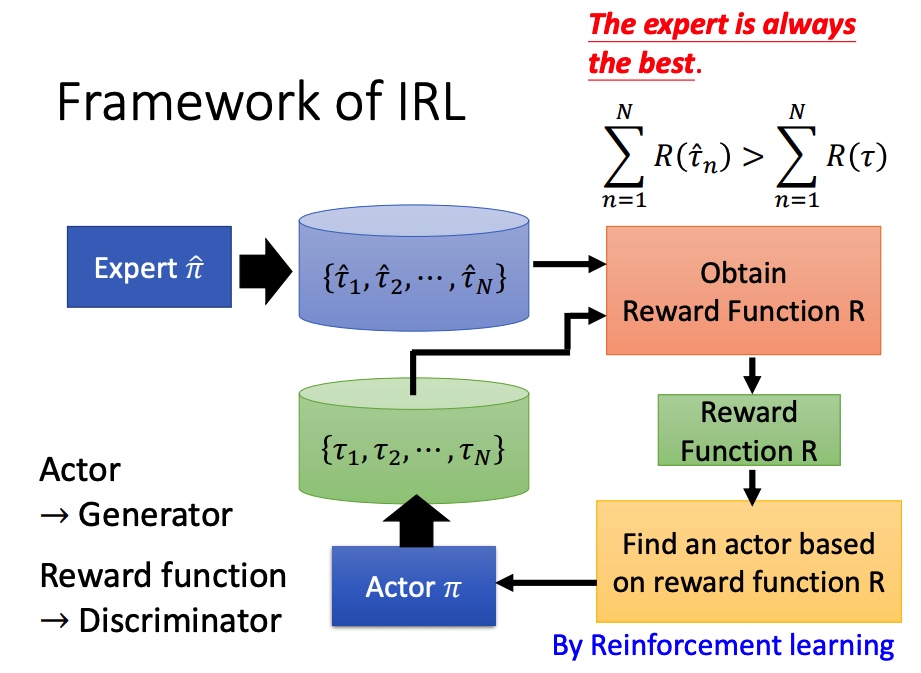
类似于 GAN 的训练方法(actor 换成 generator,reward function 换成 discriminator)。
学到 actor 的 pi 后,调整 reward function,保证专家的行为得分大于学到的行为。
李宏毅强化学习课程笔记 Imitation Learning
https://blog.xiang578.com/post/reinforce-learnning-basic-imitation-learning.html