李宏毅强化学习课程笔记 Sparse Reward
我的笔记汇总:
- Policy Gradient、PPO: Proximal Policy Optimization、Q-Learning
- Actor Critic
- Sparse Reward
- Imitation Learning
Reward Shaping
如果 reward 分布非常稀疏的时候,actor 会很难学习,所以刻意设计 reward 引导模型学习。
Curiosity Intrinsic Curiosity module (ICM)
在原来 Reward 函数的基础上,引入 ICM 函数。ICM 鼓励模型去探索新的动作。最后 ICM 和 Reward 和越大越好。
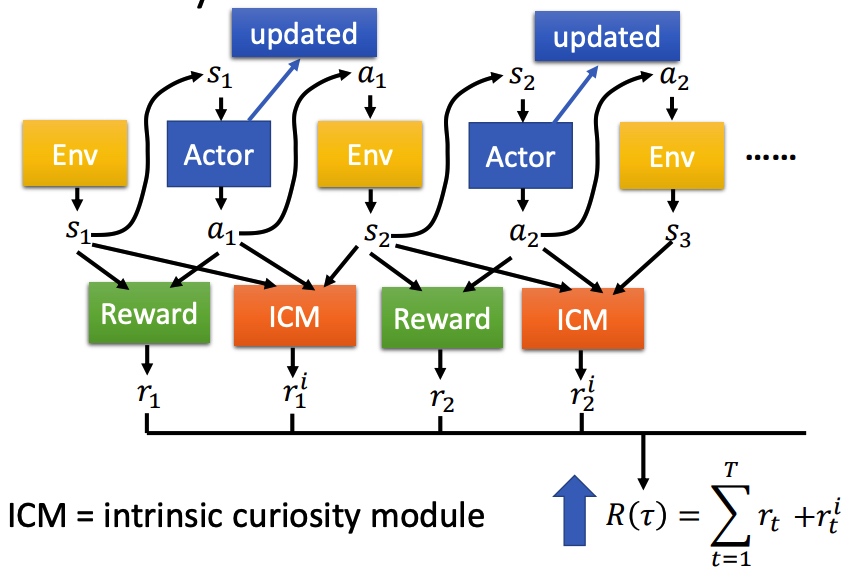
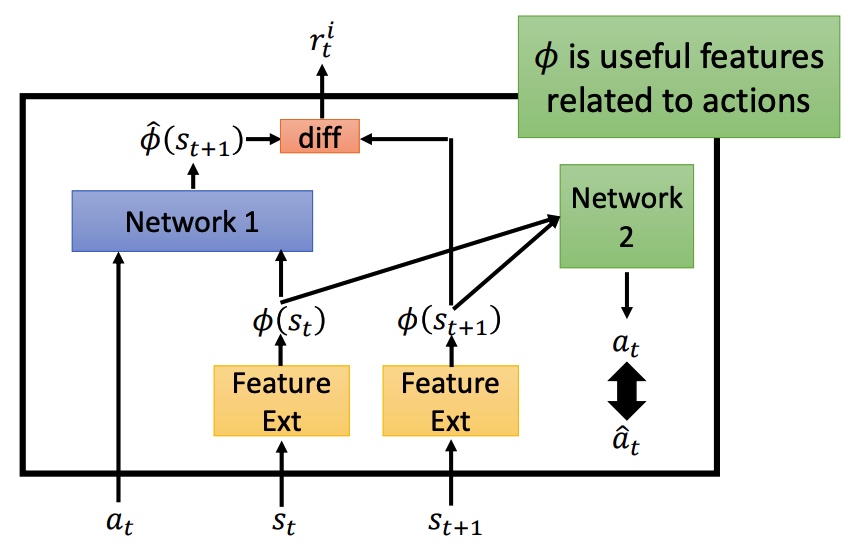
鼓励探索新动作之后,会导致系统风险变大。对比预测的下一个状态和真正的状态的差异程度进行抑制。

Feature Ext 对状态进行抽取,过滤没有意义的内容。
Network 1 预测下一个状态,然后再和真实状态计算 diff 程度。
Network 2 预测 action,和真实的 action 进行对比。如果两个 action 接近,说明 f 可以进行特征提取。重要程度计算。
Curriculum Learning
规划学习路线,从简单任务学习。
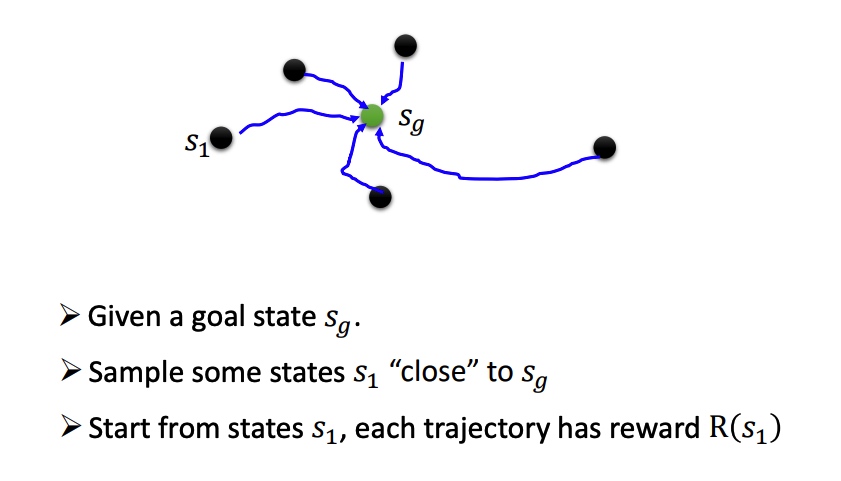
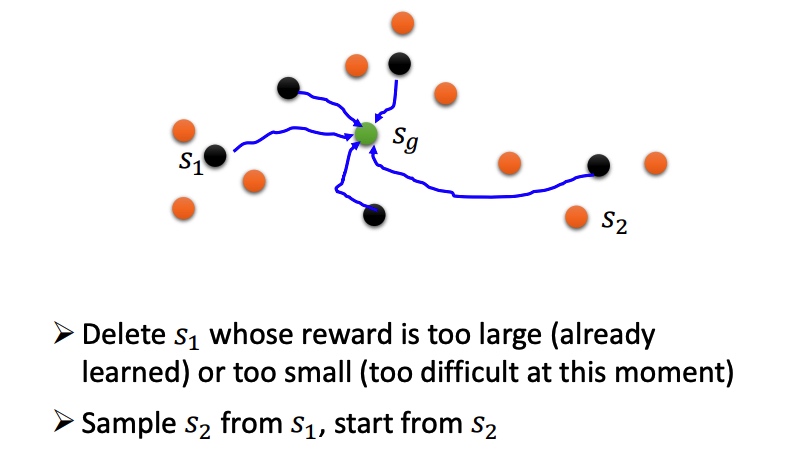
Reverse Curriculum Generation
Hierarchical Reinforcement Learning
对 agent 分层,高层负责定目标,分配给底层 agent 执行。如果低一层的agent没法达到目标,那么高一层的agent会受到惩罚(高层agent将自己的愿景传达给底层agent)。
如果一个agent到了一个错误的目标,那就假设最初的目标本来就是一个错误的目标(保证已经实现的成果不被浪费)
李宏毅强化学习课程笔记 Sparse Reward
https://blog.xiang578.com/post/reinforce-learnning-basic-sparse-reward.html