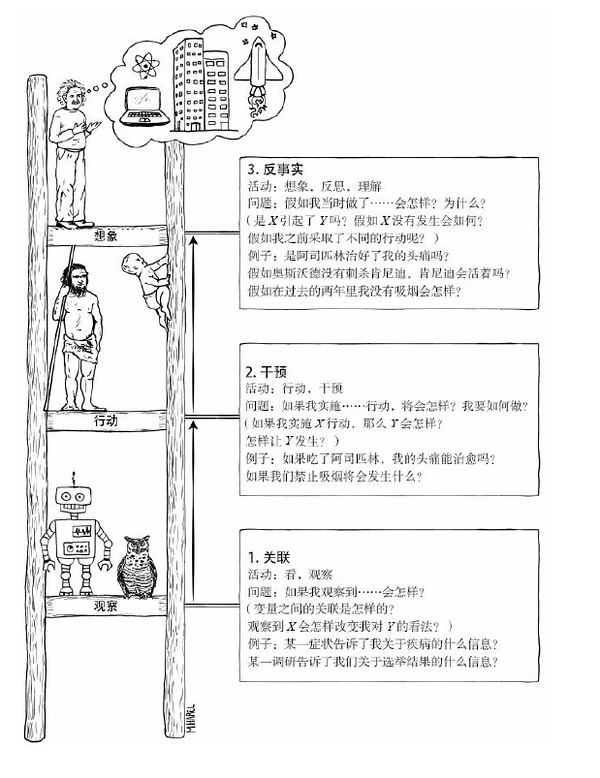
PCH Pearl’s Causal Hierarchy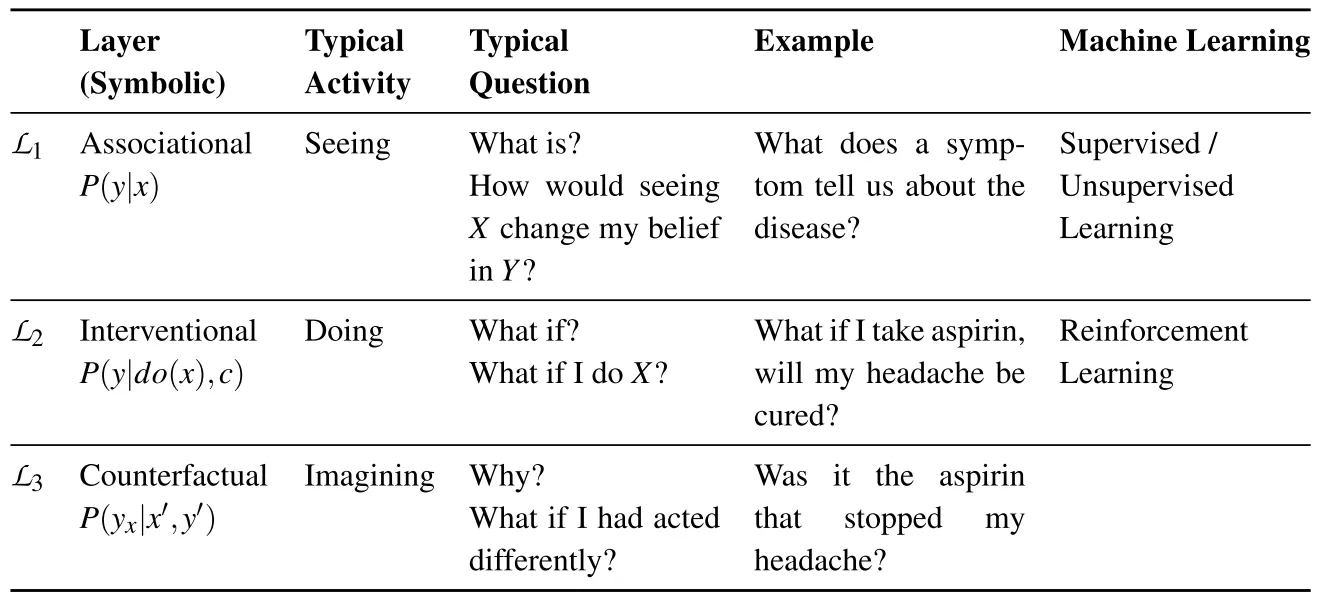
因果关系者掌握三种不同层级的认知能力:观察能力(seeing)、行动能力(doing)和想象能力(imagining)。
第一层对应观察到的世界,第二层对应的是一个可被观察的美好新世界,第三层对应无法被观察到的世界。
- 第一层级是观察能力,具体而言是指发现环境中的规律的能力。在认知革命发生之前,这种能力为许多动物和早期人类所共有。
- 关联:统计学,当前深度学习,依赖数据,缺乏灵活性和适应性
- 第二层级是行动能力,涉及预测对环境进行刻意改变后的结果,并根据预测结果选择行为方案以催生出自己期待的结果。
- 干预比关联更高级,因为它不仅涉及被动观察,还涉及主动改变现状。
- 干预:参考过去的数据,不能解决当前的行为。比如之前的涨价是由于其他原因导致的。AB实验
- 第三层想象能力
- 反事实,对事件干预后进行反思