强化学习(Reinforcement Learning,RL),是指一类从**(与环境)交互中不断学习**的问题以及解决这类问题的方法。
- 强化学习问题可以描述为一个智能体从与环境的交互中不断学习以完成特定目标(比如取得最大奖励值)。
- 和深度学习类似,强化学习中的关键问题也是贡献度分配问题,每一个动作并不能直接得到监督信息,需要通过整个模型的最终监督信息(奖励)得到,并且有一定的延时性。
强化学习(Reinforcement Learning,RL),是指一类从**(与环境)交互中不断学习**的问题以及解决这类问题的方法。
【时间序列预测】Are Transformers Effective for Time Series Forecasting?
香港中文大学曾爱玲文章,在长时间序列预测问题上使用线性模型打败基于 Transformer 的模型,并对已有模型的能力进行实验分析(灵魂7问,强烈推荐好好读一下!)。
滴滴和华南理工在 2022 年 KDD 上发表的 ETA 论文,从多个视角解释轨迹,引入 Hierarchical Self-Attention Network 方法进行建模,最终在滴滴内部数据集上获得指标提升。
【Uber ETA】DeeprETA An ETA Post-processing System at Scale
本篇文章充满工业界风格,介绍 Uber 如何构建基于深度学习的 ETA 系统。在 Uber App 中,ETA 主要服务网约车和外卖两大业务,基于业务发展产生出一些细分场景的 ETA 需求(pick-up、drop-off)。技术挑战在于偏航(系统预估路线和司机真实路线不同)、不同场景数据分布不同、不同场景对 ETA 诉求不同,所以他们主要目标是构建高效以及泛用的 ETA 系统。
国庆节前突然对如何计算 BERT 的参数量感兴趣,不过一直看不明白网上的计算过程,索性下载 BERT 源代码阅读一番。这篇文章记录阅读 BertModel 类(核心代码实现)时写的一些笔记,反正我也是纸上谈兵,所以不需要太关注数据处理和 Finetune 相关部分,最后附上计算 BERT 参数量的过程仅供参考。
李宏毅强化学习课程笔记 Imitation Learning
我的笔记汇总:
apprenticeship learning
学习专家的行为。
监督学习,但是样本有限。
Dataset Aggregation
如果机器的学习能力有限,可能复制专家多余无用的动作。监督学习无法区分哪些是需要学习、哪些是需要忽视的行为。
监督学习中,我们假设训练数据和测试数据有相同的分布。Behavior Cloning 中可能分布不同。

反向强化学习
没有 reward 函数,通过专家和环境互动学到一个 reward function,然后再训练 actor。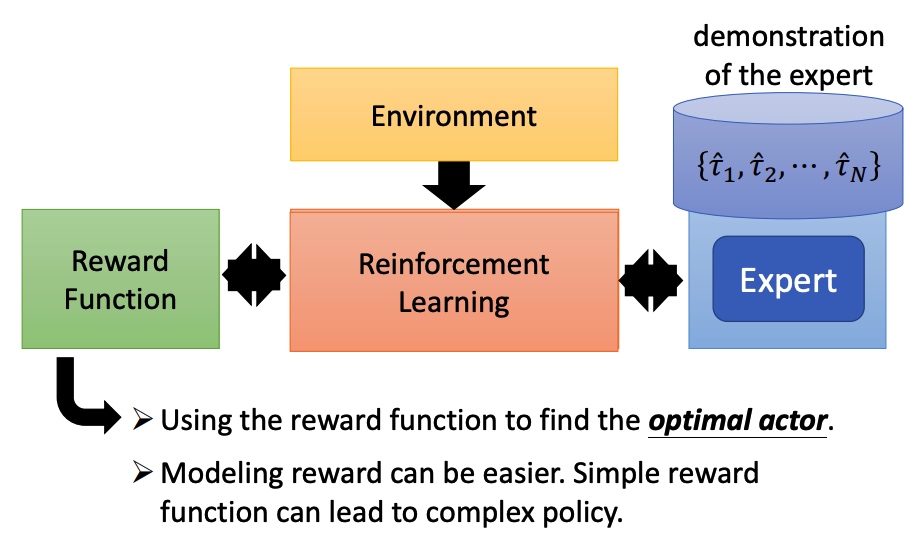
类似于 GAN 的训练方法(actor 换成 generator,reward function 换成 discriminator)。
学到 actor 的 pi 后,调整 reward function,保证专家的行为得分大于学到的行为。
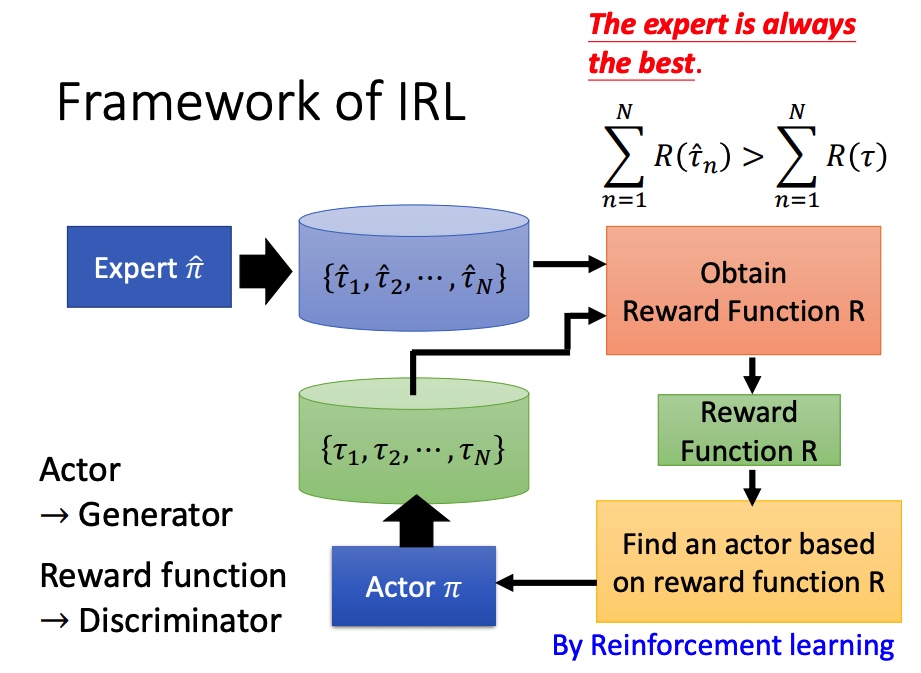
我的笔记汇总:
如果 reward 分布非常稀疏的时候,actor 会很难学习,所以刻意设计 reward 引导模型学习。
在原来 Reward 函数的基础上,引入 ICM 函数。ICM 鼓励模型去探索新的动作。最后 ICM 和 Reward 和越大越好。
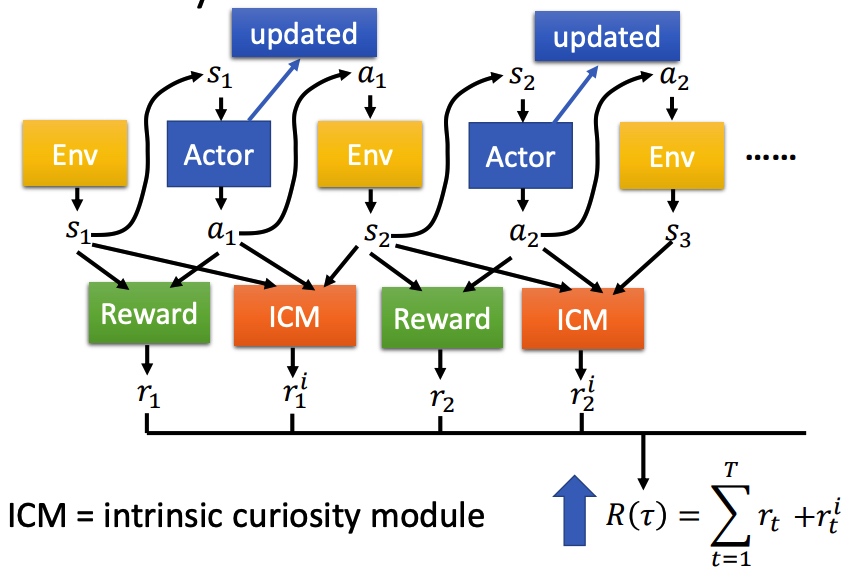
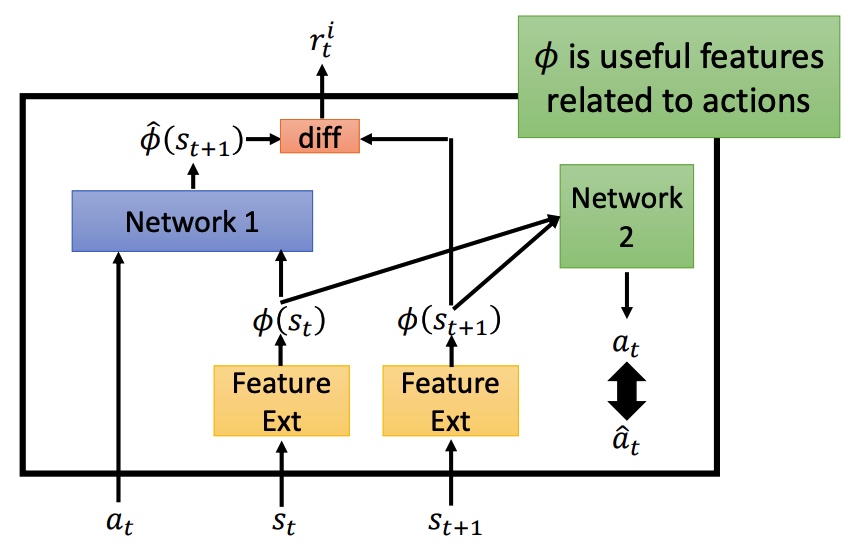
鼓励探索新动作之后,会导致系统风险变大。对比预测的下一个状态和真正的状态的差异程度进行抑制。

Feature Ext 对状态进行抽取,过滤没有意义的内容。
Network 1 预测下一个状态,然后再和真实状态计算 diff 程度。
Network 2 预测 action,和真实的 action 进行对比。如果两个 action 接近,说明 f 可以进行特征提取。重要程度计算。
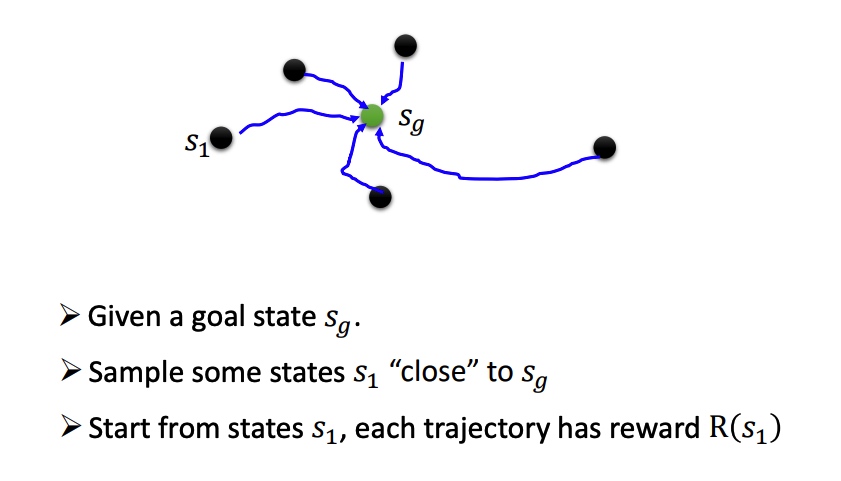
规划学习路线,从简单任务学习。
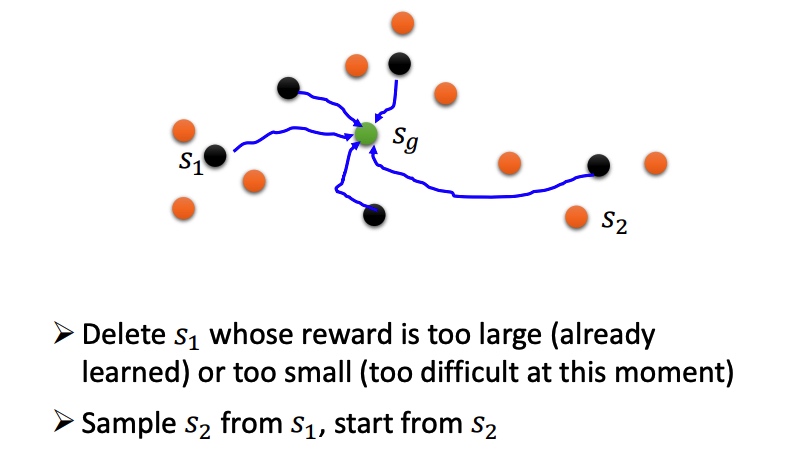
Reverse Curriculum Generation
对 agent 分层,高层负责定目标,分配给底层 agent 执行。如果低一层的agent没法达到目标,那么高一层的agent会受到惩罚(高层agent将自己的愿景传达给底层agent)。
如果一个agent到了一个错误的目标,那就假设最初的目标本来就是一个错误的目标(保证已经实现的成果不被浪费)
我的笔记汇总:

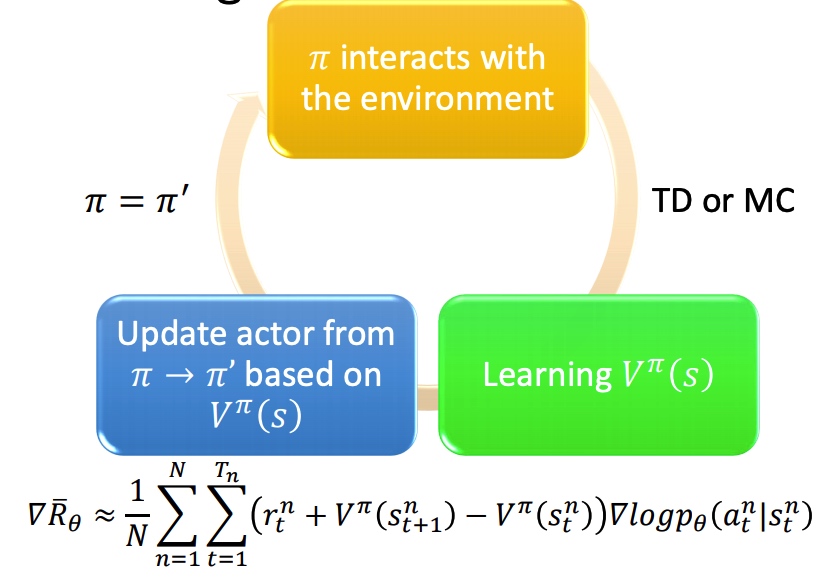
状态价值函数 $V^{\pi}(s)$
状态行动价值函数 $Q^{\pi}(s,a)$
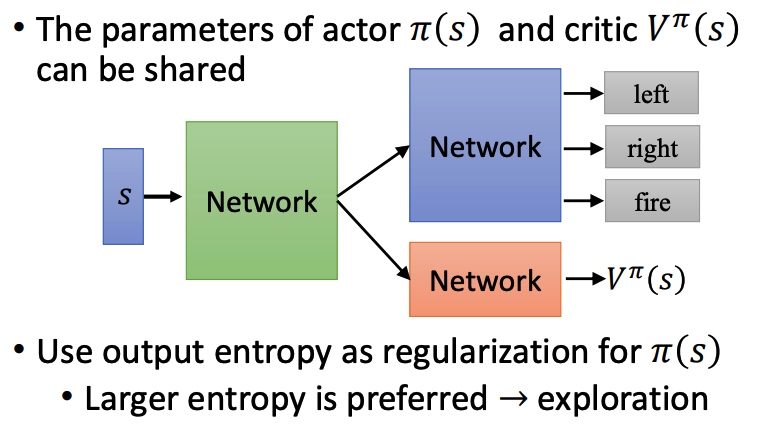
用 V 和 Q 替换 PG 中的累积 reward 和 baseline。新的模型需要训练两个网络,比较困难。
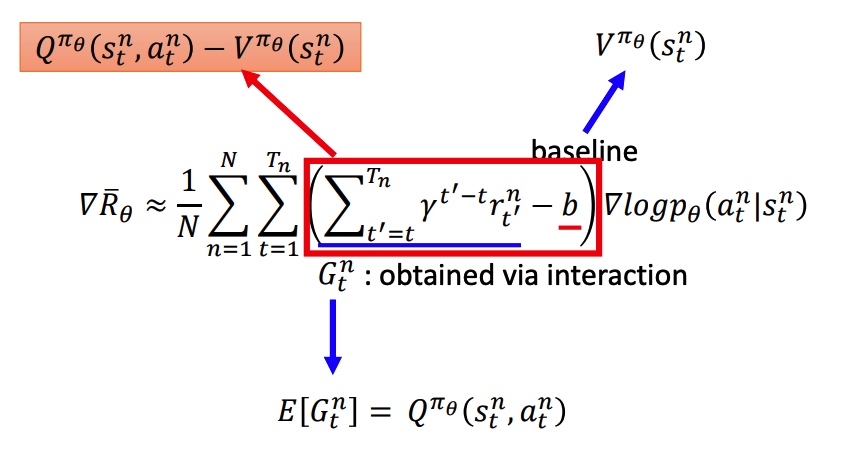
用 V 去替代 Q,能降低模型整体方差(MC 到 TD)。最下面两个公式转化是由实验得到。

训练过程:
tip:
该网络不仅仅告诉 actor 某一个 action 的好坏,还告诉 actor 应该返回哪一个 action。

将这个 actor 返回的 action 和 state 一起输入到一个固定的 Q,利用梯度上升更新 actor。
完整的训练过程和 conditional GAN 类似, actor 是 generator,Q 是 discriminator。
算法:


GBDT(Gradient Boosting Decision Tree) 从名字上理解包含三个部分:提升、梯度和树。它最早由 Freidman 在 greedy function approximation :a gradient boosting machine 中提出。很多公司线上模型是基于 GBDT+FM 开发的,我们 Leader 甚至认为 GBDT 是传统的机器学习集大成者。断断续续使用 GBDT 一年多后,大胆写一篇有关的文章和大家分享。
假设有一个游戏:给定数据集 ${(x_1,y_1),(x_2,y_2),…,(x_n,y_n)}$,寻找一个模型${\hat y=F(x_i)}$,使得平方损失函数 ${\sum \frac{1}{2}(\hat y_i - y_i)^2}$ 最小。
如果你的朋友提供一个可以使用但是不完美的模型,比如
$$F(x_1)=0.8,y_1=0.9$$
$$F(x_2)=1.4,y_2=1.3$$
在如何不修改这个模型的参数情况下,提高模型效果?
一个简单的思路是:重新训练一个模型实现
$$F(x_1)+h(x_1)=y_1$$
$$F(x_2)+h(x_2)=y_2$$
$$…$$
$$F(x_n)+h(x_n)=y_n$$
换一个角度是用模型学习数据 ${(x_1,y_1-F(x_1)),(x_2,y_2-F(x_2)),…,(x_n,y_n-F(x_n))}$。得到新的模型 ${\hat y=F(x_i)+h(x_i)}$。
其中 ${y_i-F(x_i)}$ 的部分被我们称之为残差,即之前的模型没有学习到的部分。重新训练模型 ${h(x)}$正是学习残差。如果多次执行上面的步骤,可以将流程描述成:
$${F_0(x)}$$
$${F_1(x)=F_0(x)+h_1(x)}$$
$${F_2(x)=F_1(x)+h_2(x)}$$
$${…}$$
$${F_t(x)=F_t-1(x)+h_t(x)}$$
即 ${F(x;w)=\sum^T_{t=1}h_t(x;w)}$,这也就是 GBDT 。
Gradient Boosting Decision Tree 简称 GBDT,最早由 Friedman 在论文《Greedy function approximation: a gradient boosting machine》中提出。简单从题目中理解包含三个部分内容:Gradient Descent、Boosting、Decision Tree。
Decision Tree 即决策树,利用超平面对特征空间划分来预测和分类,根据处理的任务不同分成两种:分类树和回归树。在 GBDT 算法中,用到的是 CART 即分类回归树。用数学语言来描述为 ${F={f(x)=w_{q(x)}}}$,完成样本 ${x}$ 到决策树叶子节点 ${q(x)}$ 的映射,并将该叶子节点的权重 ${w_{q(x)}}$ 赋给样本。CART 中每次通过计算 gain 值贪心来进行二分裂。
Boosting 是一种常用的集成学习方法(另外一种是 Bagging)。利用弱学习算法,反复学习,得到一系列弱分类器(留一个问题,为什么不用线性回归做为弱分类器)。然后组合这些弱分类器,构成一个强分类器。上面提到的模型 ${F(x;w)=\sum^T_{t=1}h_t(x)}$ 即是一种 boosting 思路,依次训练多个 CART 树 ${h_i}$,并通过累加这些树得到一个强分类器 ${F(x;w)}$。
在 2 中我提到 GBDT 包括三个部分并且讲述了 Boosting 和 Decison Tree。唯独没有提到 Gradient Descent,GBDT 的理论依据却恰恰和它相关。
回忆一下,Gradient Descent 是一种常用的最小化损失函数 ${L(\theta)}$ 的迭代方法。
在 1 中提到的问题中,损失函数是 MSE ${L(y, F(x))=\frac{1}{2}(y_i - f(x_i))^2}$。
我们的任务是通过调整 ${F(x_1), F(x_2), …, F(x_n)}$ 最小化 ${J=\sum_i L(y_i, F(x_i))}$。
如果将 ${F(x_i)}$ 当成是参数,并对损失函数求导得到 ${ \frac{\partial J}{\partial F(x_i)} = \frac{\partial \sum_i L(y_i, F(x_i))}{\partial F(x_i)} = \frac{\partial L(y_i, F(x_i))}{\partial F(x_i)} = F(x_i)-y_i}$。
可以发现,在 1 中提到的模型 ${h(x)}$ 学习的残差 ${y_i-F(x_i)}$正好等于负梯度,即 ${y_i-F(x_i)=-\frac{\partial J}{\partial F(x_i)}}$。
所以,参数的梯度下降和函数的梯度下降原理上是一致的:
模型 F 定义为加法模型:
$${F(x;w)=\sum^{M}{m=1} \alpha_m h_m(x;w_m) = \sum^{M}{m=1}f_t(x;w_t)}$$
其中,x 为输入样本,h 为分类回归树,w 是分类回归树的参数,${\alpha}$ 是每棵树的权重。
通过最小化损失函数求解最优模型:${F^* = argmin_F \sum^N_{i=1}L(y_i, F(x_i))}$
输入: ${(x_i,y_i),T,L}$
说明:
这一篇就先到这里,之后还会分享 GBDT 常用损失函数推导以及 XGboost 相关内容。如果有任何想法,都可以在留言区和我交流。
(FTRL) Follow The Regularized Leader
FTRL 是 Google 提出的一种优化算法。常规的优化方法例如梯度下降、牛顿法等属于批处理算法,每次更新需要对 batch 内的训练样本重新训练一遍。在线学习场景下,我们希望模型迭代速度越快越好。例如用户发生一次点击行为后,模型就能快速进行调整。FTRL 在这个场景中能求解出稀疏化的模型。
FTL(Follow The Leader) 算法:每次找到让之前所有损失函数之和最小的参数。
$$W=argmin_W \sum^t_{i=1}F_i(W)$$
FTRL 中的 R 是 Regularized,可以很容易猜出来在 FTL 的基础上加正则项。
$$W=argmin_W \sum^t_{i=1}F_i(W) + R(W)$$
FTRL 的损失函数直接很难求解,一般需要引入一个代理损失函数 $h(w)$。代理损失函数常选择比较容易求解析解以及求出来的解和优化原函数得到的解差距不能太大。
我们通过两个解之间的距离 Regret 来衡量效果:
$$
\begin{array}{c}{w_{t}=\operatorname{argmin}{w} h{t-1}(w)} \ {\text {Regret}{t}=\sum{t=1}^{T} f_{t}\left(w_{t}\right)-\sum_{t=1}^{T} f_{t}\left(w^{*}\right)}\end{array}
$$
其中 $w^{*}$ 是直接优化 FTRL 算法得到的参数。当距离满足 $\lim {t \rightarrow \infty} \frac{\text {Regret}{t}}{t}=0$,损失函数认为是有效的。其物理意义是,随着训练样本的增加,两个优化目标优化出来的参数效果越接近。
参数 $w_{t+1}$ 的迭代公式:
$${w_{t+1}=argmin_w{ g_{(1:t)}w + \frac{1}{2} \sum_{s=1}^t \sigma_s \lVert w - w_s \rVert ^2 + \lambda_1 \lVert W \rVert_1 + \frac{1}{2} \lambda_2 \lVert W \rVert^2 }}$$
其中 $g_{(1:t)}=\sum^{t}{s=1}g_s$,$g_s$ 为 $f(w_s)$ 的次梯度。参数 $\sum^t{s=1}\sigma_s=\frac{1}{\eta _t}$,学习率 $\eta _t = \frac{1}{\sqrt{t}}$,随着迭代轮数增加而减少。
展开迭代公式
$${F(w)= g_{(1:t)}w + \frac{1}{2} \sum_{s=1}^t \sigma_s \lVert w - w_s \rVert ^2 + \lambda_1 \lVert W \rVert_1 + \frac{1}{2} \lambda_2 \lVert W \rVert^2 }$$
$${F(w)= g_{(1:t)}w + \frac{1}{2} \sum_{s=1}^t \sigma_s ( w^Tw - 2w^Tw_s + w_s^Tw_s) + \lambda_1 \lVert W \rVert_1 + \frac{1}{2} \lambda_2 \lVert W \rVert^2 }$$
$${F(w)= (g_{(1:t)} - \sum_{s=1}^t \sigma_s w_s)w + \frac{1}{2} (\sum_{s=1}^t \sigma_s + \lambda_2) w^Tw + \lambda_1 \lVert W \rVert_1 + const }$$
$${F(w)= z_t^Tw + \frac{1}{2} (\frac{1}{\eta _t} + \lambda_2) w^Tw + \lambda_1 \lVert W \rVert_1 + const }$$
其中 ${z_{t-1}=g^{(1:t-1)} - \sum_{s=1}^{t-1} \sigma_s w_s}$。
对 $F(w)$ 求偏导得到:
$${z_t + (\frac{1}{\eta _t} + \lambda_2) w + \lambda_1 \partial \lvert W \rvert = 0}$$
$w$ 和 $z$ 异号时,等式成立。
根据基础知识里面提到的对于 L1 正则利用偏导数代替无法求解的情况,得到:
$$
\partial|W|=\left{\begin{array}{ll}{0,} & {\text { if }-1<w<1} \ {1,} & {\text { if } w>1} \ {-1,} & {\text { if } w<-1}\end{array}\right.
$$
因此可得:
$$
w_{i}=\left{\begin{array}{ll}{0,} & {\text { if }\left|z_{i}\right| \leq \lambda_{1}} \ {\frac{-\left(z_{i}-\text sgn(z_i) \lambda_{1}\right)}{\eta_{t}+\lambda_{2}},} & {\text { if others }}\end{array}\right.
$$
将 SGD 的迭代公式写成:${W^{t+1}=W^t - \eta _tg_t}$
FTRL 迭代公式为:${W^{t+1}=argmin_w{ G^{(1:t)}W + \lambda_1 \lVert W \rVert_1 +\lambda_2 \frac{1}{2} \lVert W \rVert }}$
代入 ${\sum^t_{s=1}\sigma _s= \frac{1}{\eta t}}$ 到上面的公式中,得到 ${W^{t+1}=argmin_w{ \sum_t^{s=1}g_sW + \frac{1}{2} \sum^t{s=1}\sigma _s\lVert W - W_s \rVert_2^2 }}$
求偏导得到 ${\frac{\partial f(w)}{\partial w} = \sum^t_{s=1}g_s + \sum^t_{s=1}\sigma _s( W - W_s )}$
令偏导等于 0 :${\sum^t_{s=1}g_s + \sum^t_{s=1}\sigma _s( W^{t+1} - W_s ) = 0}$
化简得到:${(\sum^t_{s=1}\sigma s) W^{t+1} = \sum^t{s=1}\sigma s W^{s} - \sum^t{s=1}g_s}$
代入 $\sigma$:${\frac{1}{\eta t} W^{t+1} = \sum^t{s=1}\sigma s W^{s} - \sum^t{s=1}g_s}$
根据上一个公式得出上一轮的迭代公式:${\frac{1}{\eta {t-1}} W^{t} = \sum^{t-1}{s=1}\sigma s W^{s} - \sum^{t-1}{s=1}g_s}$
两式相减:${\frac{1}{\eta _t} W^{t+1} - \frac{1}{\eta _{t-1}} W^{t} = (\frac{1}{\eta _t} - \frac{1}{\eta _{t-1}}) W_t - g_t}$
最终化简得到和 SGD 迭代公式相同的公式:${W_{t+1} = W_t - \eta_t g_t}$
引用自论文 Ad Click Prediction: a View from the Trenches
下面的伪代码中学习率和前面公式推导时使用的一些不一样: $\eta_{t_{i}}=\frac{\alpha}{\beta+\sqrt{\sum_{s=1}^{t} g_{s_{i}}^{2}}}$。Facebook 在 GBDT + LR 的论文中研究过不同的学习率影响,具体可以参看博文 Practical Lessons from Predicting Clicks on Ads at Facebook(gbdt + lr) | 算法花园。

FM 是工业界常用的机器学习算法,在之前博文 (FM)Factorization Machines 中有简单的介绍。内部的 FTRL+FM 代码没有开源,所以也不好分析。从 FM+FTRL算法原理以及工程化实现 - 知乎 中找了一张 FTRL+FM 的伪代码图片。

课件下载:Hung-yi Lee - Deep Reinforcement Learning
课程视频:DRL Lecture 1: Policy Gradient (Review) - YouTube
我的笔记汇总:
强化学习基本定义:
一些符号:
Policy Network 最后输出的是概率。
目标:调整 actor 中神经网络 policy $\pi(\theta)$,得到 $a=\pi(s, \theta)$,最大化 reward。
trajectory $\tau$ 由一系列的状态和动作组成,出现这种组合的概率是 $p_{\theta}(\tau)$ 。
$$
\begin{array}{l}{p_{\theta}(\tau)} \ {\quad=p\left(s_{1}\right) p_{\theta}\left(a_{1} | s_{1}\right) p\left(s_{2} | s_{1}, a_{1}\right) p_{\theta}\left(a_{2} | s_{2}\right) p\left(s_{3} | s_{2}, a_{2}\right) \cdots} \ {\quad=p\left(s_{1}\right) \prod_{l=1}^{T} p_{\theta}\left(a_{t} | s_{t}\right) p\left(s_{t+1} | s_{t}, a_{t}\right)}\end{array}
$$
reward :根据 s 和 a 计算得分 r,求和得到 R。在围棋等部分任务中,无法获得中间的 r(下完完整的一盘棋后能得到输赢的结果)。
需要计算 R 的期望 $\bar{R}_{\theta}$,形式和 GAN 类似。如果一个动作得到 reward 多,那么就增大这个动作出现的概率。最终达到 agent 所做 policy 的 reward 一直都比较高。
$$
\bar{R}{\theta}=\sum{\tau} R(\tau) p_{\theta}(\tau)
$$
强化学习中,没有 label。需要从环境中采样得到 $\tau$ 和 R,根据下面的公式去优化 agent。相当于去求一个 likelihood。
$\nabla f(x) = f(x) \frac{\nabla f(x)}{f(x)}= f(x) \nabla \log f(x)$ ,这一步中用到对 log 函数进行链式求导。
$$
\nabla \bar{R}{\theta}=\sum{\tau} R(\tau) \nabla p_{\theta}(\tau)
$$
$$
\begin{array}{l}{=E_{\left.\tau \sim p_{\theta}(\tau)[R(\tau)] \log p_{\theta}(\tau)\right]} \approx \frac{1}{N} \sum_{n=1}^{N} R\left(\tau^{n}\right) \nabla \log p_{\theta}\left(\tau^{n}\right)} \ {=\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_{n}} R\left(\tau^{n}\right) \nabla \log p_{\theta}\left(a_{t}^{n} | s_{t}^{n}\right)}\end{array}
$$
参数更新方法:

训练 actor 的过程看成是分类任务:输入 state ,输出 action。
最下面公式分别是反向传播梯度计算和 PG 的反向梯度计算,PG 中要乘以整个轨迹的 R。
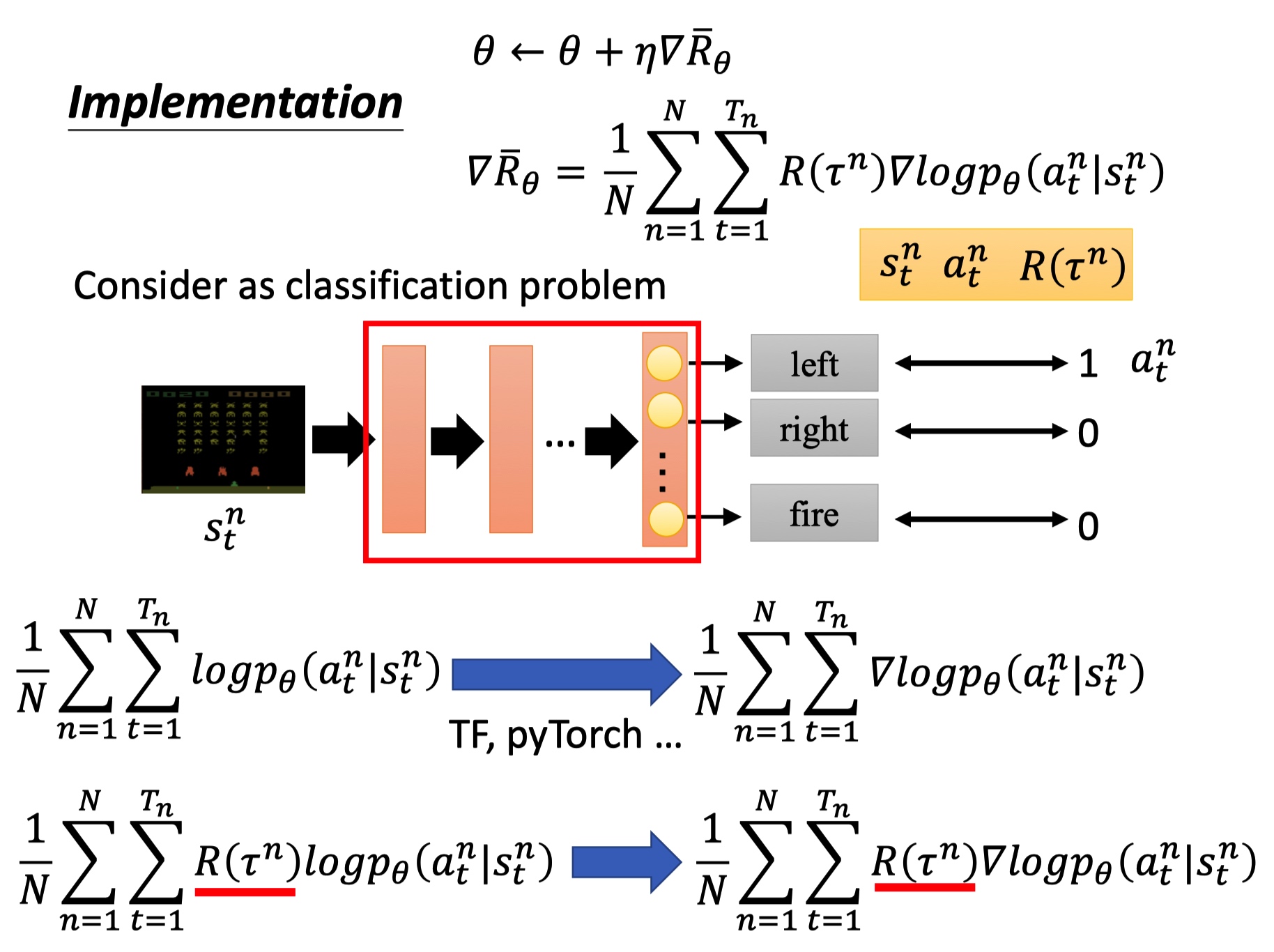
tip 1: add a baseline
强化学习的优化和样本质量有关,避免采样不充分。Reawrd 函数变成 R-b,代表回报小于 b 的都被我们当成负样本,这样模型能去学习得分更高的动作。b 一般可以使用 R 的均值。
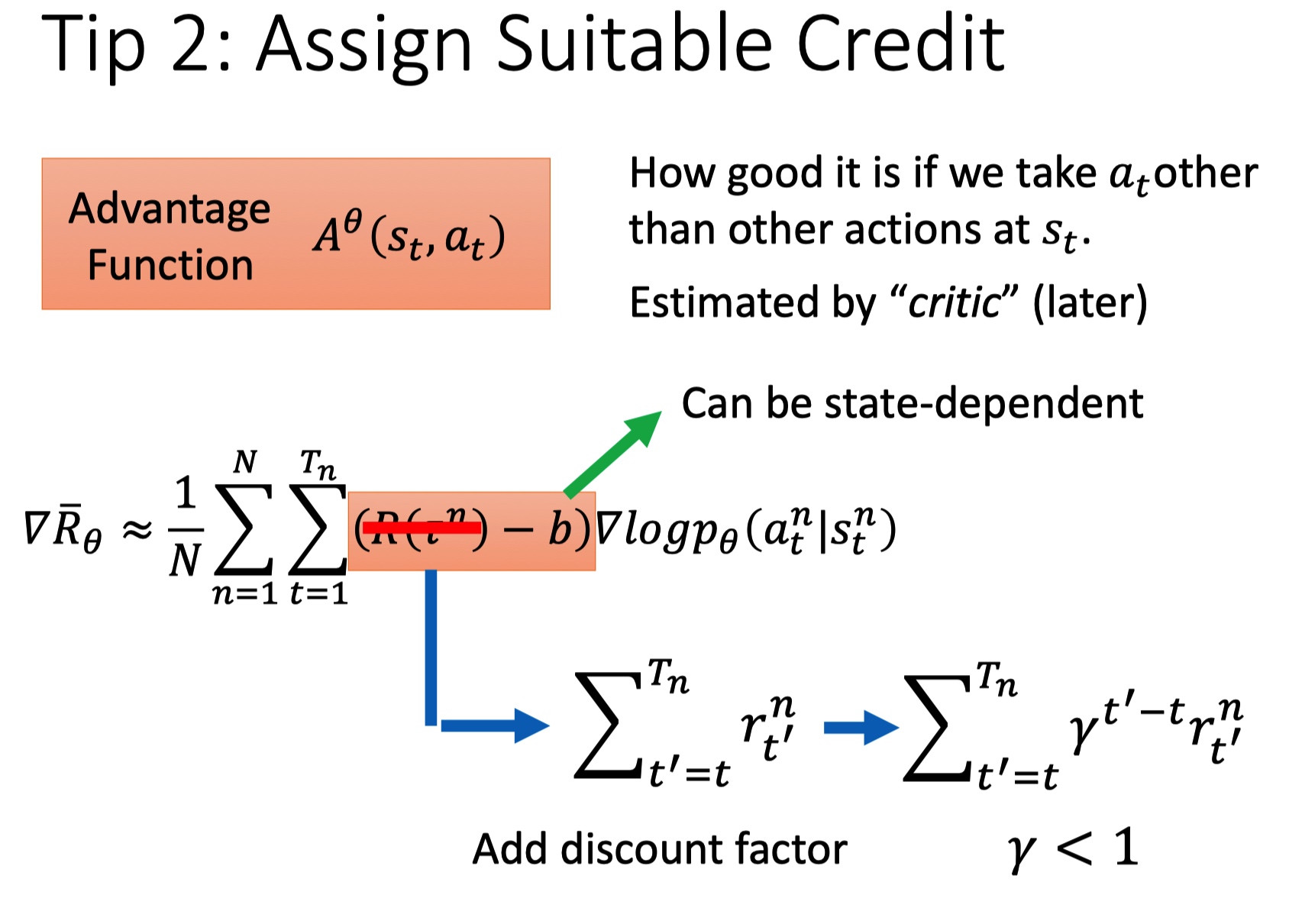
tip 2: assign suitable credit
一场游戏中,不论动作好坏,总会乘上相同的权重 R,这种方法是不合理的,希望每个 action 的权重不同。
假设需要估计期望 $E_{x~p[f(x)]}$,x 符合 p 分布,将期望写成积分的形式。由于在 P 分布下面很难采样,把问题转化到已知 q 分布上,得到在 p 分布下计算期望公式。
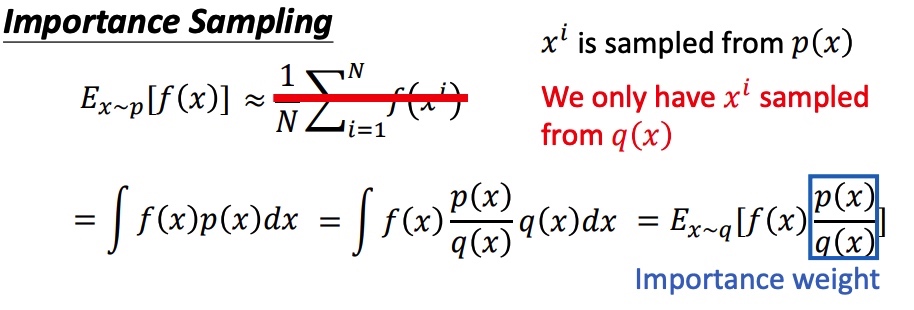
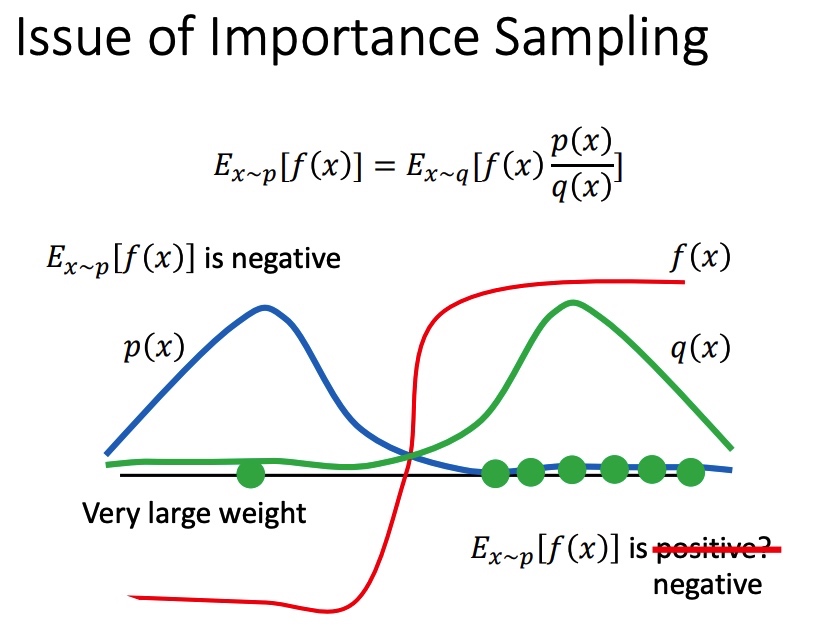
上面方法得到 p 和 q 期望接近,但是方差可能相差很大,且和 $\frac{p(x)}{q(x)}$ 有关。
原分布的方差:
$$
\operatorname{Var}{x-p}[f(x)]=E{x-p}\left[f(x)^{2}\right]-\left(E_{x-q}[f(x)]\right)^{2}
$$
新分布的方差:
$$
\begin{array}{l}{\operatorname{Var}{x \sim p}[f(x)]=E{x \sim p}\left[f(x)^{2}\right]-\left(E_{x \sim p}[f(x)]\right)^{2}} \ {\operatorname{Var}{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right]=E{x \sim q}\left[\left(f(x) \frac{p(x)}{q(x)}\right)^{2}\right]-\left(E_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right]\right)^{2}} \ {=E_{x \sim p}\left[f(x)^{2} \frac{p(x)}{q(x)}\right]-\left(E_{x \sim p}[f(x)]\right)^{2}}\end{array}
$$
在 p 和 q 分布不一致时,且采样不充分时,可能会带来比较大的误差。
on-policy 时,PG 每次参数更新完成后,actor 就改变了,不能使用之前的数据,必须和环境重新互动收集数据。引入 $p_{\theta \prime}$ 进行采样,就能将 PG 转为 off-ploicy。

和之前相比,相当于引入重要性采样,所以也有前一节中提到的重要性采样不足问题。
$$
J^{\theta^{\prime}}(\theta)=E_{\left(s_{t}, a_{t}\right) \sim \pi_{\theta^{\prime}}}\left[\frac{p_{\theta}\left(a_{t} | s_{t}\right)}{p_{\theta^{\prime}}\left(a_{t} | s_{t}\right)} A^{\theta^{\prime}}\left(s_{t}, a_{t}\right)\right]
$$
为了克服采样的分布与原分布差距过大的不足,PPO 引入 KL 散度进行约束。KL 散度用来衡量两个分布的接近程度。
$$
J_{P P O}^{\theta^{\prime}}(\theta)=J^{\theta^{\prime}}(\theta)-\beta K L\left(\theta, \theta^{\prime}\right)
$$
TRPO(Trust Region Policy Optimization),要求 $K L\left(\theta, \theta^{\prime}\right)<\delta$。
$$
J_{T R P O}^{\theta^{\prime}}(\theta)=E_{\left(s_{t}, a_{t}\right) \sim \pi_{\theta^{\prime}}}\left[\frac{p_{\theta}\left(a_{t} | s_{t}\right)}{p_{\theta^{\prime}}\left(a_{t} | s_{t}\right)} A^{\theta^{\prime}}\left(s_{t}, a_{t}\right)\right]
$$
KL 散度可能比较难计算,在实际中常使用 PPO2。

系数 $\beta$ 在迭代的过程中需要进行动态调整。引入 $KL_{max} KL_{min}$,KL > KLmax,说明 penalty 没有发挥作用,增大 $\beta$。

value-base 方法,利用 critic 网络评价 actor 。通过状态价值函数 $V^{\pi}(s)$ 来衡量预期的期望。V 和 pi、s 相关。
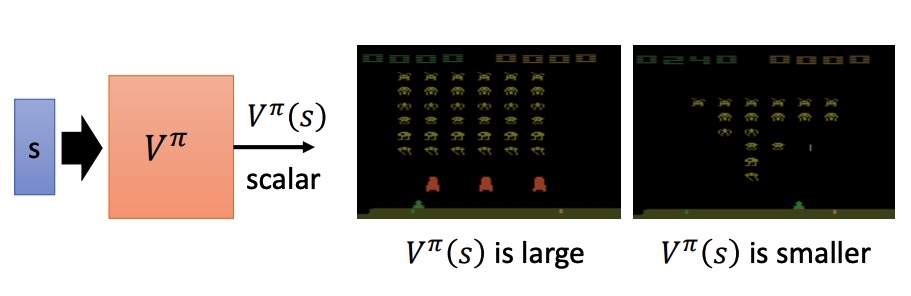
MC: 根据策虑 $\pi$ 进行游戏得到最后的 $G(a)$,最终存在方差大的问题。$\operatorname{Var}[k X]=k^{2} \operatorname{Var}[X]$
TD: r 的方差比较小,$V^{\pi}(s_{t+1})$ 在采样不充分的情况下,可能不准确。

State-action value function $Q^{\pi}(s, a)$:预测在 pi 策略下,pair(s, a) 的值。相当于假设 state 情况下强制采取 action a。
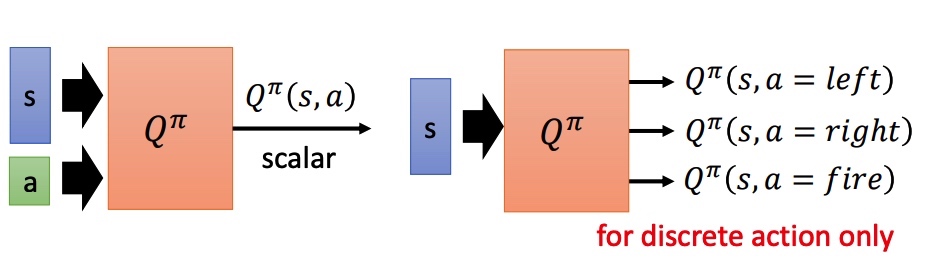
对于非分类的方法:
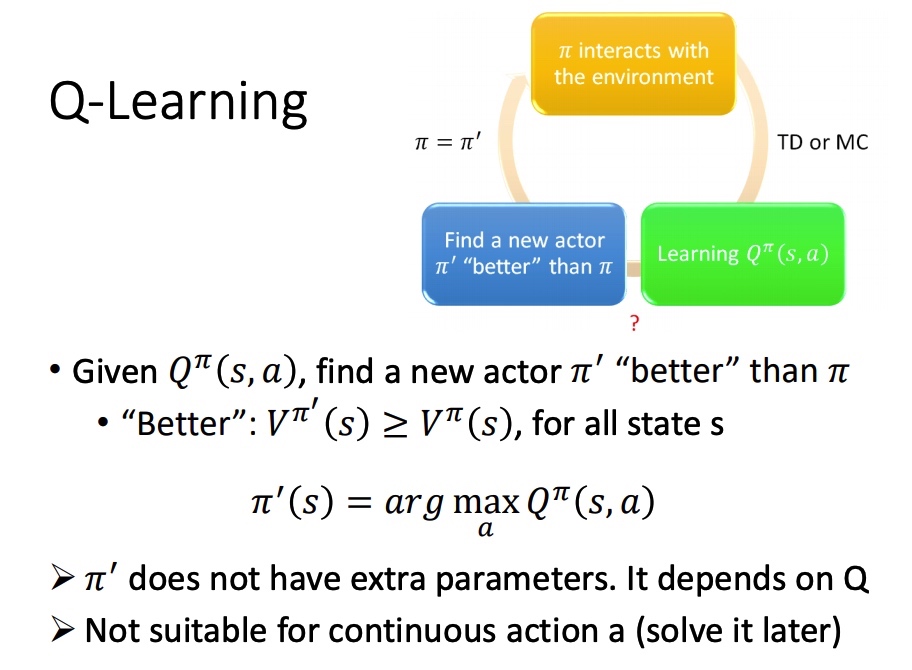
Q-Learning
在给定 state 下,分别代入 action,取函数值最大的 a,作为后面对该 state 时采取的 action。
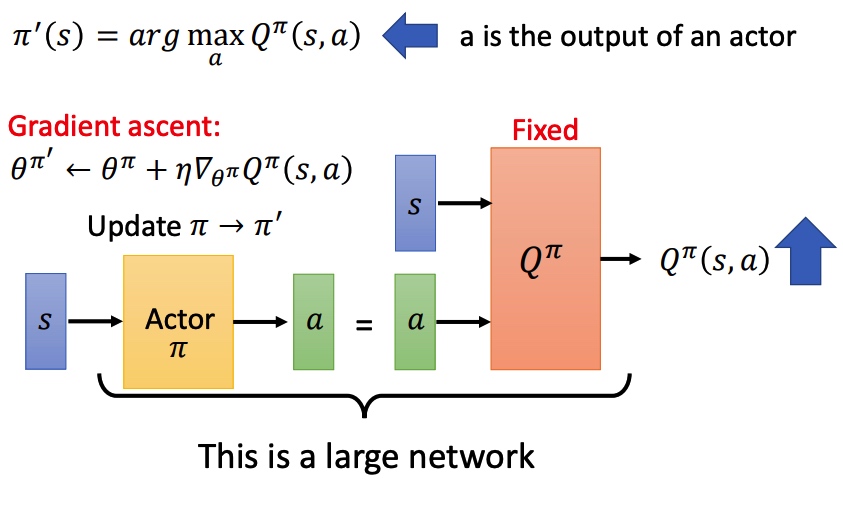
证明新的策虑存在:
左右两边的网络相同,如果同时训练比较困难。简单的想法是固定右边的网络进行训练,一定次数后再拷贝左边的网络。
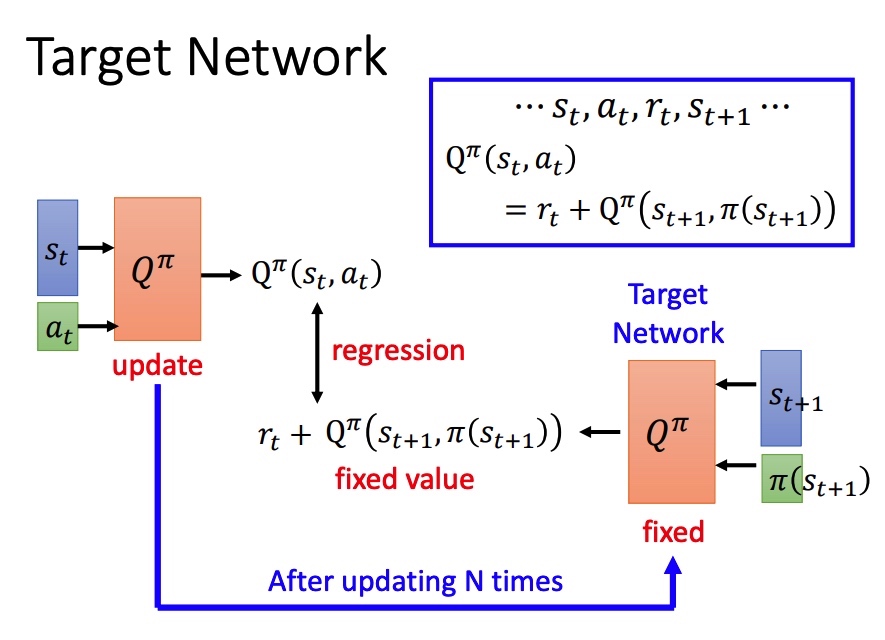
Q function 导致 actor 每次都会选择具有更大值的 action,无法准确估计某一些动作,对于收集数据而言是一个弊端。

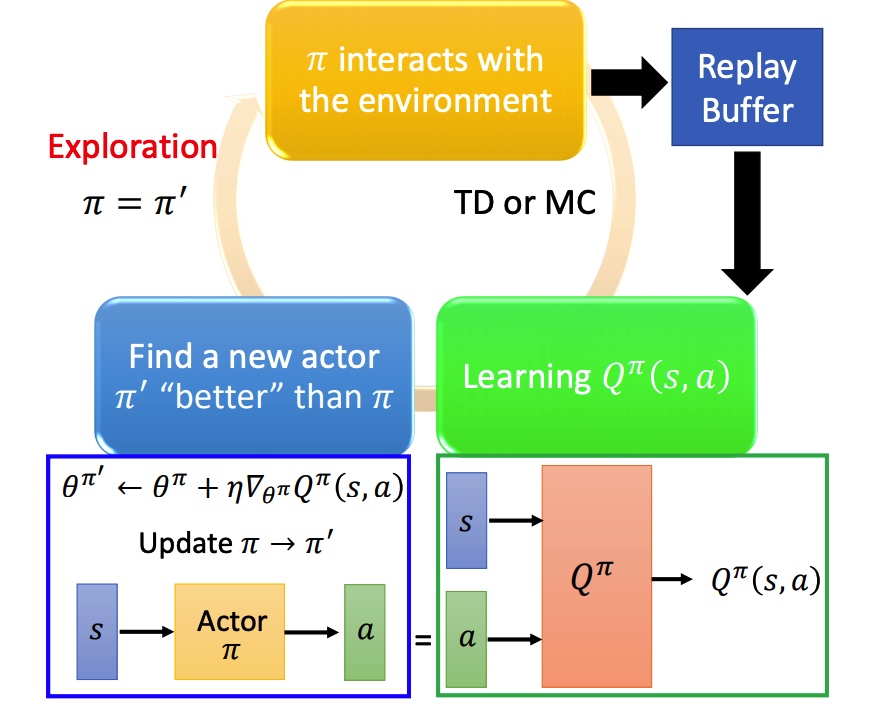
采样之后的 $(s_t, a_t, r_t, s_{t+1})$ 保存在一个 buffer 里面(可能是不同策虑下采样得到的),每次训练从 buffer 中 sample 一个 batch。
结果:训练方法变成 off-policy。减少 RL 重复采样,充分利用数据。
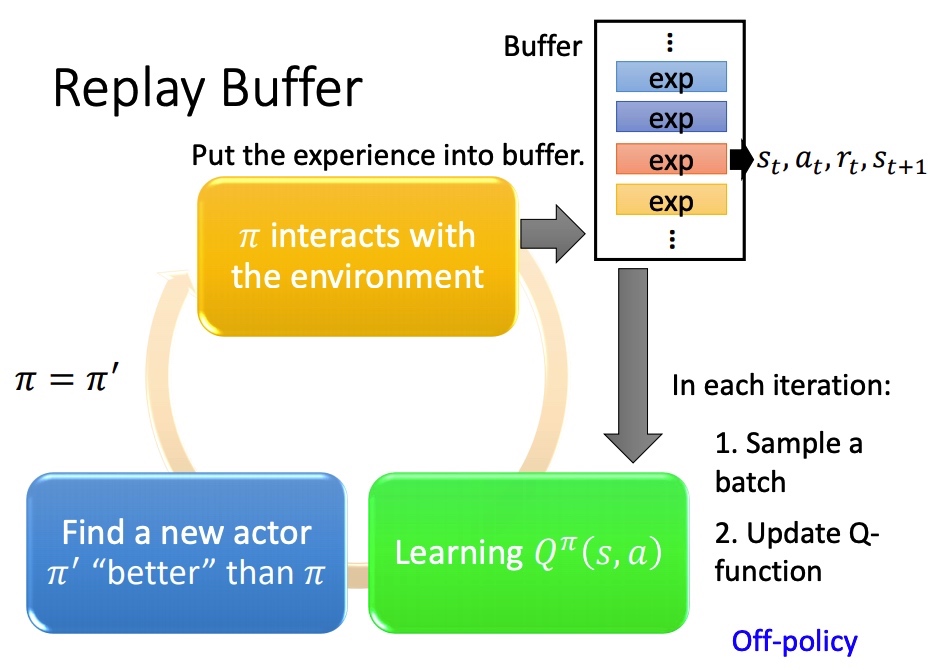
Q-Learning 流程:


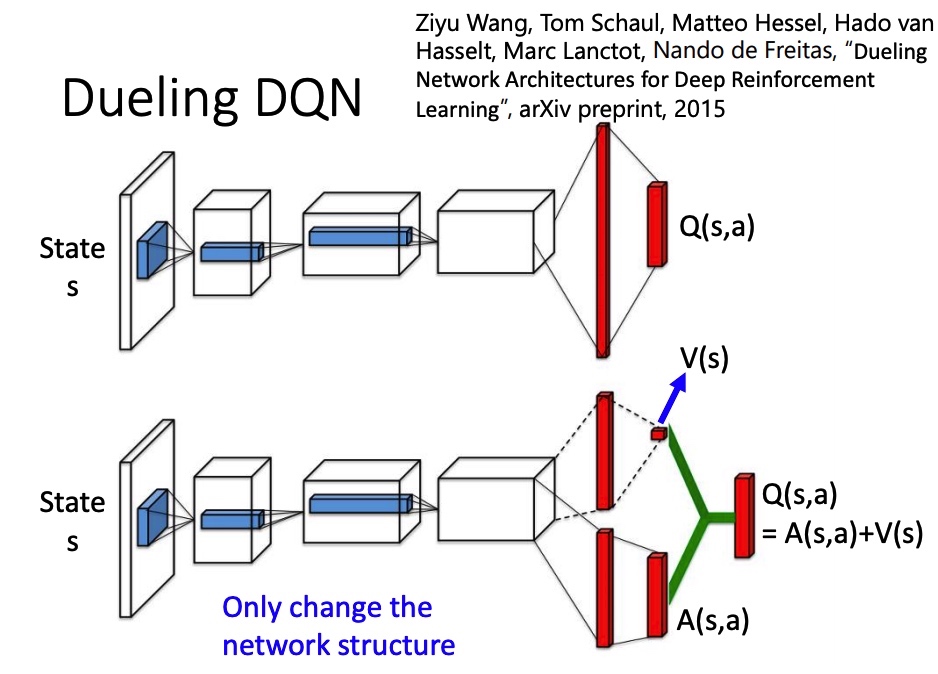
改 network 架构。V(s) 代表 s 所具有的价值,不同的 action 共享。 A(s,a) advantage function 代表在 s 下执行 a 的价值。最后 $Q(s, a) = A(s, a) + V(s)$。
为了让网络倾向于使用 V(能训练这个网络),得到 A 后,要对 A 做 normalize。
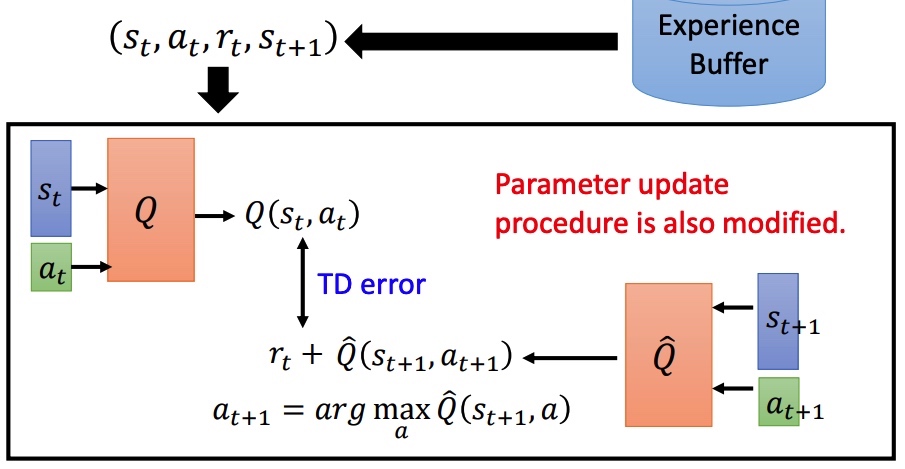
在训练过程中,对于经验 buffer 里面的样本,TD error 比较大的样本有更大的概率被采样,即难训练的数据增大被采样的概率。
综合 MC 和 TD 的优点,训练样本按一定步长 N 进行采样。MC 准确方差大,TD 方差小,估计不准。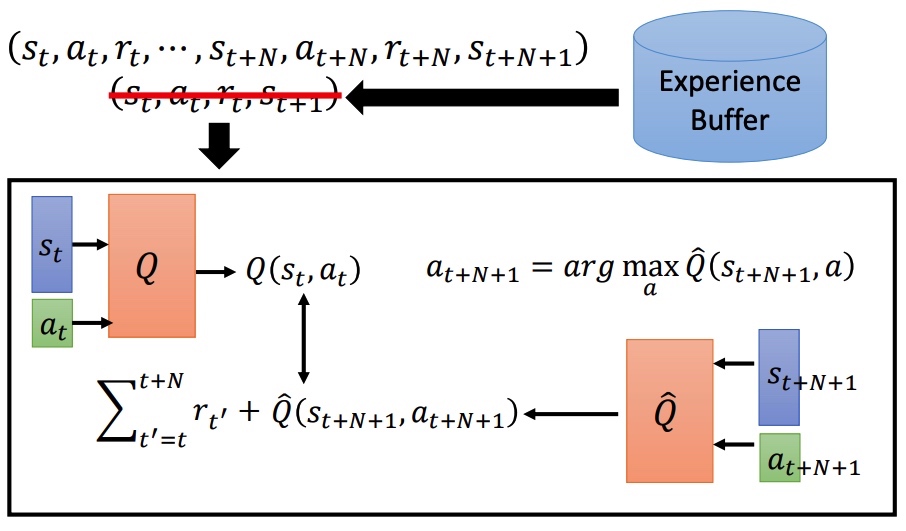

Q 是累积收益的期望,实际上在 s 采取 a 时,最终所有得到的 reward 为一个分布 reward distribution。部分时候分布不同,可能期望相同,所以用期望来代替 reward 会损失一些信息。
Distributional Q-function 直接输出分布,均值相同时,采取方差小的方案。这种方法不会产生高估 q 值的情况。
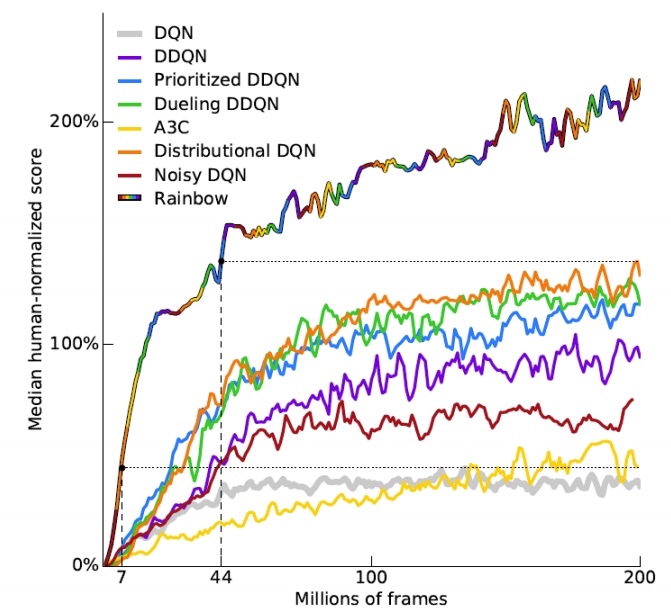
rainbow 是各种策略的混合体。
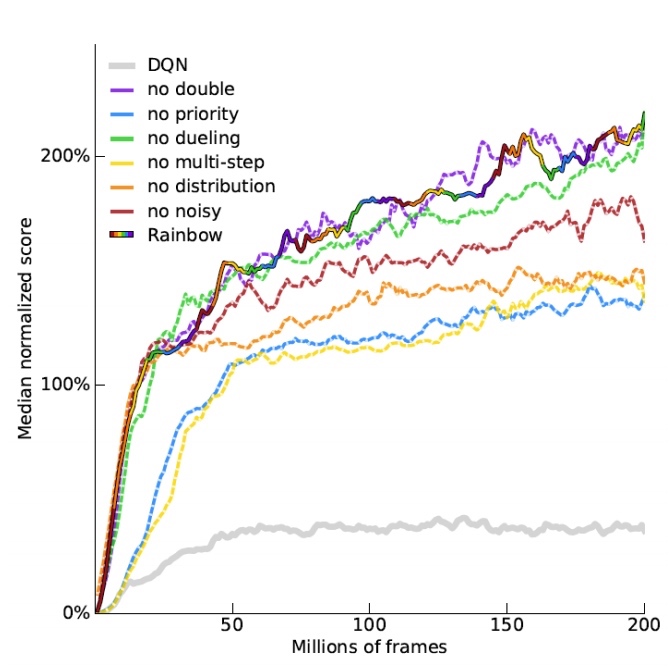
DDQN 影响不大。
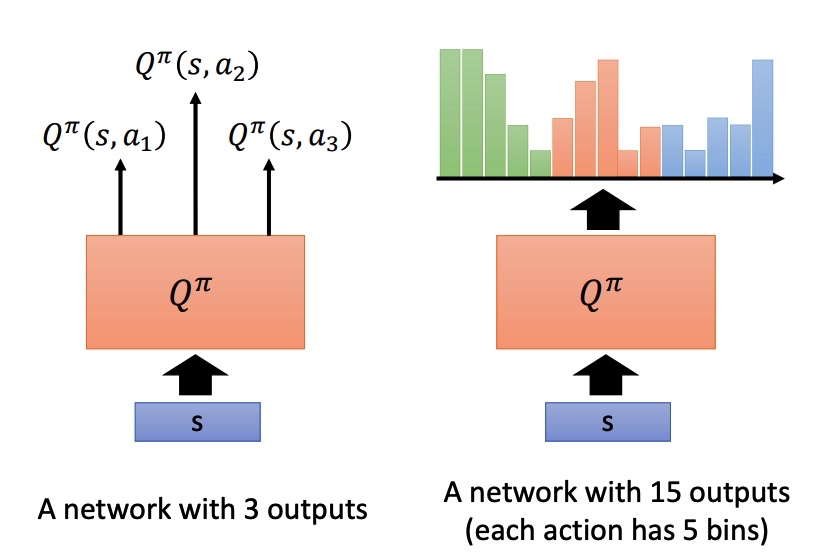
action 是一个连续的向量,Q-learning 不是一个很好的方法。
$$
a=\arg \max _{a} Q(s, a)
$$
去年学习这门做的部分笔记,现在分享出来。
笔记格式有些问题,持续整理中。

Y = wX + b
R 正则项 $$\lambda$$ 正则化参数1 | f = np.array([123, 456, 789]) # 例子中有3个分类,每个评分的数值都很大 |
W = W - learning_rate * W_grad
1 | class MultuplyGate(object): |
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC32*32*3 卷积大小 10 5*5 stride 1 pad 232*32*105*5*3+1 =76 biasActivation functions 激活函数
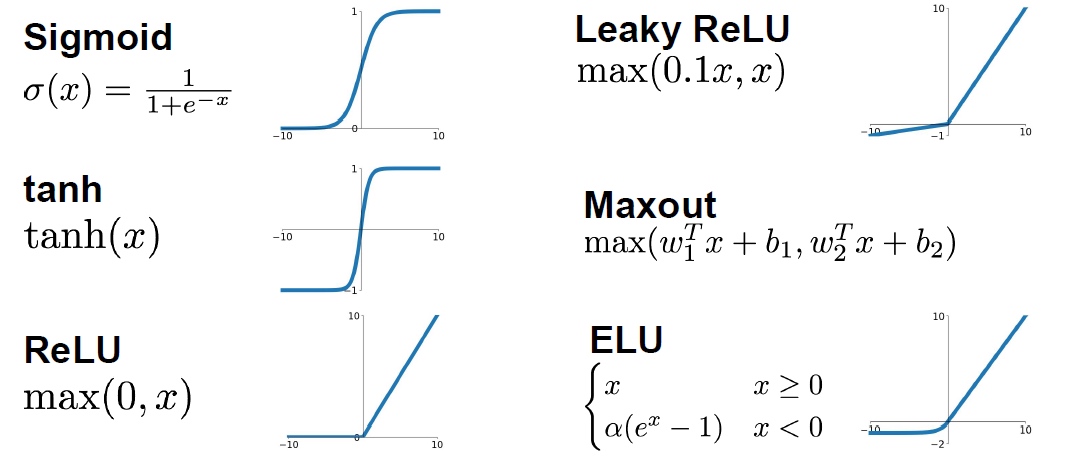
leaky_RELU(x) = max(0.01x, x)数据预处理 Data Preprocessing
1 | X -= np.mean(X, axis = 1) |
Result = gamma * normalizedX + betaSGD 的问题
x += - learning_rate * dxmini-batches GD
SGD + Momentun
V[t+1] = rho * v[t] + dx; x[t+1] = x[t] - learningRate * V[t+1]Nestrov momentum
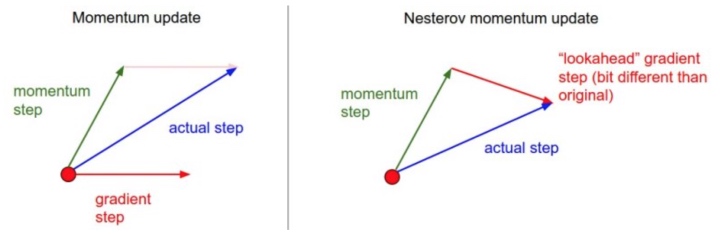
v_prev = v; v = mu * v - learning_rate * dx; x += -mu * v_prev + (1 + mu) * vAdaGrad
RMSProp
cache = decay_rate * cache + (1 - decay_rate) * dx2x += - learning_rate * dx / (sqrt(cache) + eps)Adam
where:
特点:
Learning decay
Second order optimization
CONV1: change from (11 x 11 stride 4) to (7 x 7 stride 2)CONV3,4,5: instead of 384, 384, 256 filters use 512, 1024, 512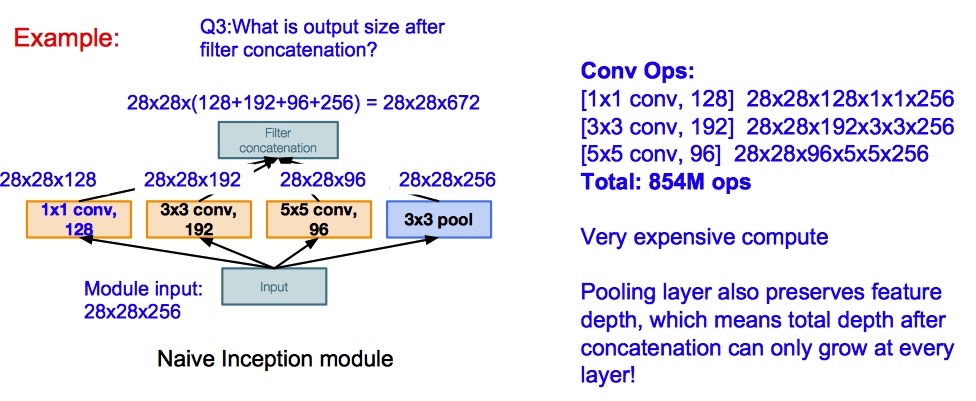
Inception module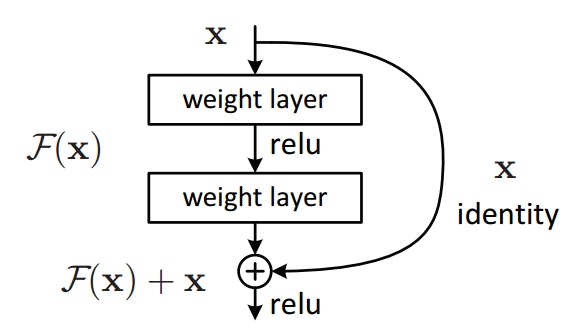
Y = (W2* RELU(W1x+b1) + b2) + X(WDR) Learning to Estimate the Travel Time
严重申明:本篇文章所有信息从论文、网络等公开渠道中获得,不会透露滴滴地图 ETA 任何实现方法。
这篇论文是滴滴时空数据组 2018 年在 KDD 上发表的关于在 ETA 领域应用深度学习的文章,里面提到模型和技巧大家都应该耳熟能详,最大亮点是工业界的创新。
简单介绍一下背景:ETA 是 Estimate Travel Time 的缩写,中文大概能翻译成到达时间估计。这个问题描述是:在某一个时刻,估计从 A 点到 B 点需要的时间。对于滴滴,关注的是司机开车把乘客从起点送到终点需要的时间。抽象出来 ETA 就是一个时间空间信息相关的回归问题。CTR 中常用的方法都可以在这里面尝试。
对于这个问题:文章首先提到一个最通用的方法 Route ETA:即在获得 A 点到 B 点路线的情况下,计算路线中每一段路的行驶时间,并且预估路口的等待时间。最终 ETA 由全部时间相加得到。这种方法实现起来很简单,也能拿到一些收益。但是仔细思考一下,没有考虑未来道路的通行状态变化情况以及路线的拓扑关系。针对这些问题,文章中提到滴滴内部也有利用 GBDT 或 FM 的方法解决 ETA 问题,不过没有仔细写实现的方法,我也不好继续分析下去。
对于 ETA 问题来说,工业界和学术界常用的指标是 MAPE(mean absolute percentage error),${y_i}$ 是司机实际从 A 点到 B 点花费的时间,${f(x_i)}$ 是 ETA 模型估计出来的时间。得到计算公式如下:
$${min_f \sum_{i=1}^{N}\frac{|y_i - f(x_i)|}{y_i}}$$
多说一句,如果使用 GBDT 模型实现 ETA 时,这个损失函数的推导有点困难,全网也没有看见几个人推导过。
这个公式主要考虑预估时间偏差大小对用户感知体验的影响,目前我们更加关心极端 badcase 对用户的影响。
模型包含 3 个部分:

上面模型中使用的特征分类:
包括两部分:离线评估和在线评估。
离线评估中取滴滴 2017 年北京前6个月的订单数据,分成两类 pickup (平台给司机分单后,司机开车去接乘客的过程)和 trip (司机接到乘客并前往目的地的过程)。具体数据集划分如下。
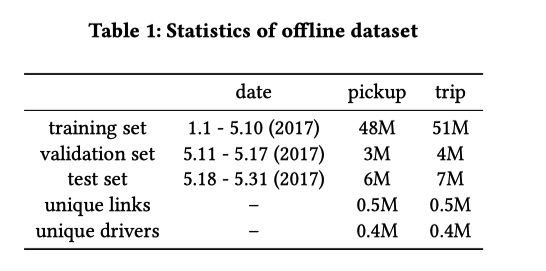
离线使用 MAPE 来评价模型。在线评估时,为了更好的与用户体验挂钩,采用多个指标来衡量 ETA 的效果。包括:
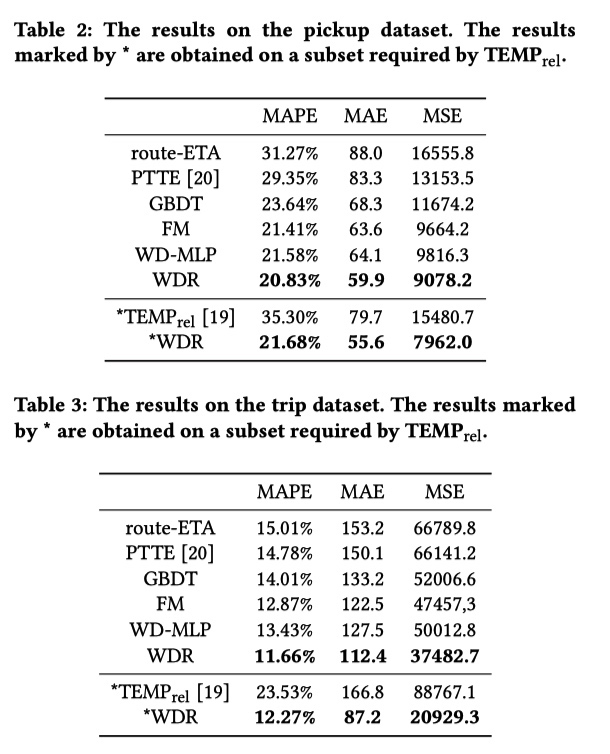
离线结果如下图所示,说来汗颜 PTTE 和 TEMP 是什么算法我都不知道…… WD-MLP 指的是将 WDR 中的 R 部分换成 MLP 。最终 WDR 较 route-ETA 有巨大提升,而且 LSTM 引入的序列信息也在 pikcup 上提升了 0.75%。文章的最后还提出来,LSTM 也可以换成是 Attention,这样替换有什么优点和缺点留给大家思考。
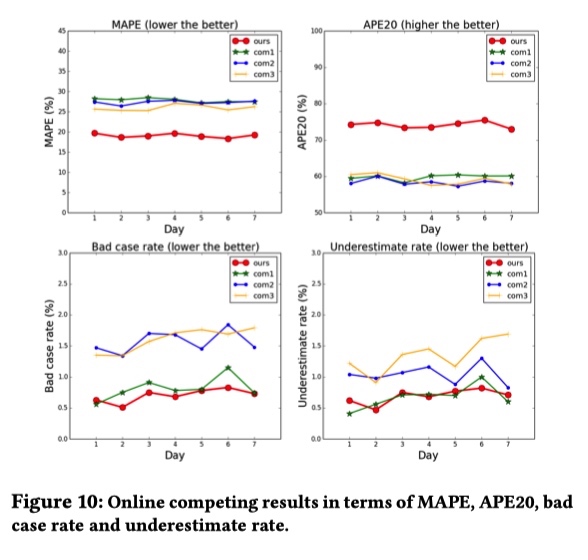
在线实验结果如下图所示,滴滴 ETA MAPE 明显小于 com1、com2、com3 ,这三家地图公司具体是哪三家,大家也能猜到吧。
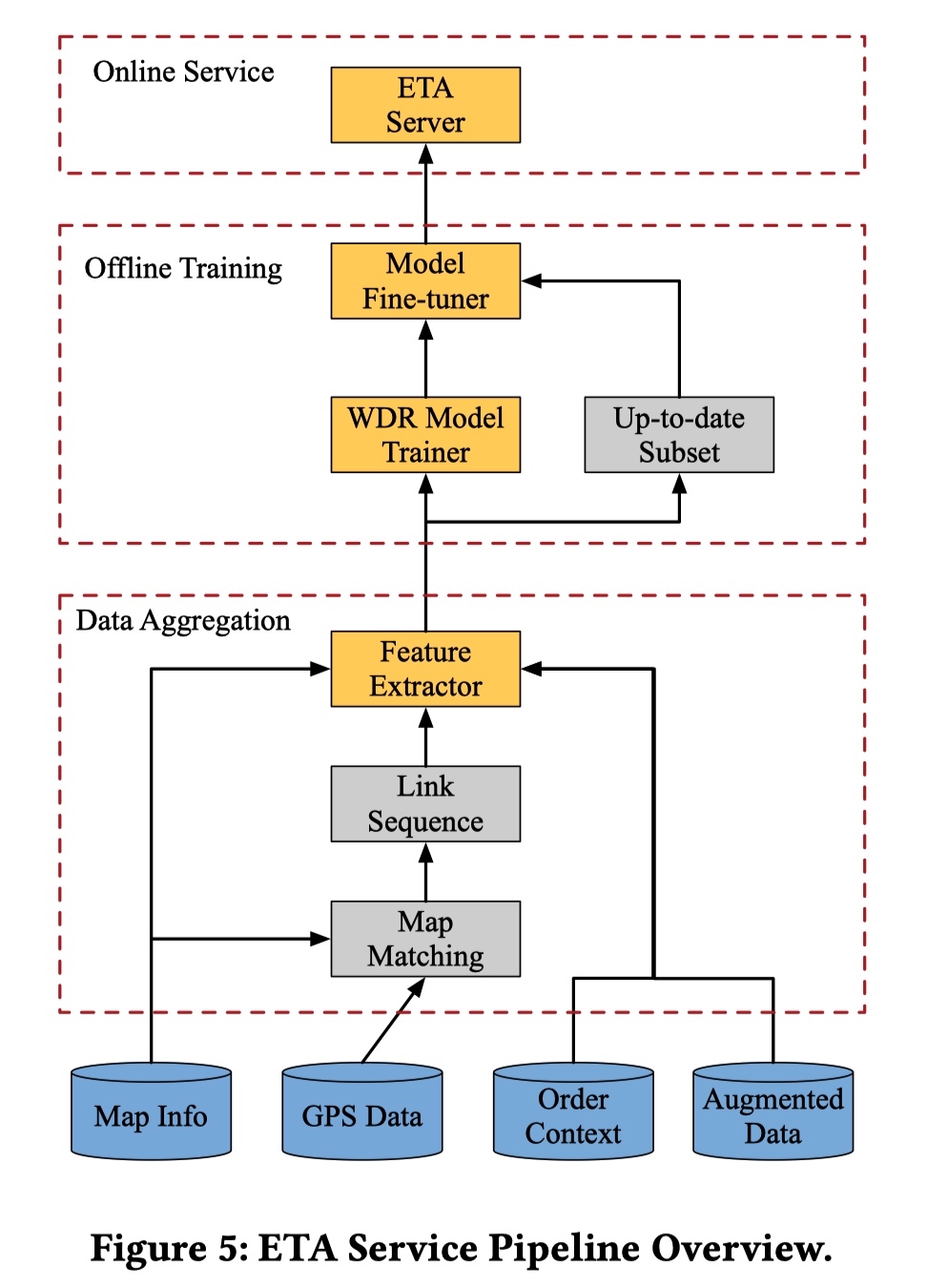
从上面的图中可以看出 ETA 服务工程架构主要包括三个部分:
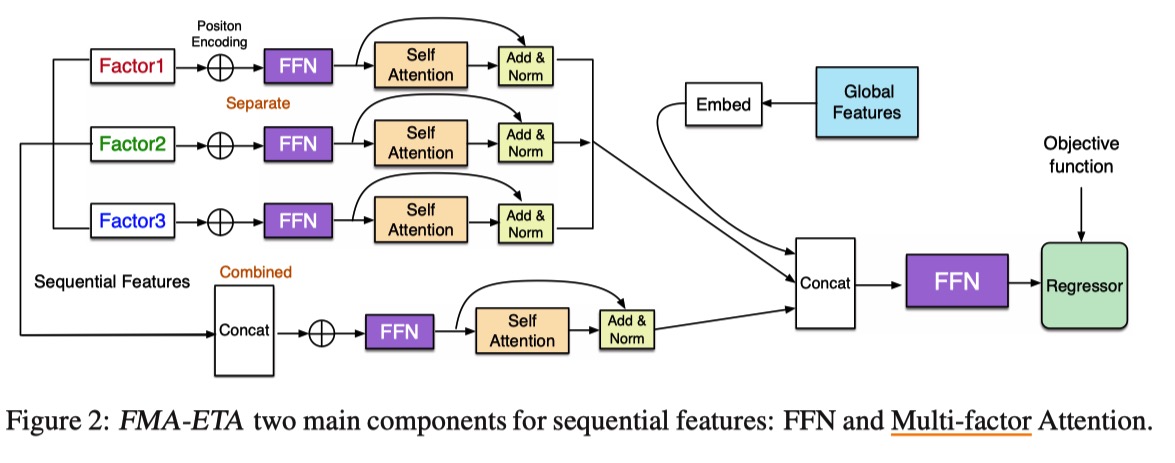
The deep modules with attention achieve better results than WDR on MAE and RMSE metrics, which means attention mechanism can help to extract features and sole the long-range dependencies in long sequence.
从上面简单的介绍来看,ETA 可以使用 CTR 和 NLP 领域的很多技术,大有可为。最后,滴滴 ETA 团队持续招人中(社招、校招、日常实习等),感兴趣者快快和我联系。
说点题外话 你为什么从滴滴出行离职? - 知乎 中提到一点:
8.同年大跃进,在滴滴中高层的眼里,没有BAT。滴滴单量超淘宝指日可待,GAFA才是滴滴要赶超的对象。百度系,LinkedIn系,学院派,uber帮,联想系,MBB就算了,据说连藤校都混成了一个小圈子。。一个项目A team ,B team。一个ETA,投入了多少人力自相残杀?MAPE做到0%又如何?用户体验就爆表了吗?长期留存就高枕无忧了吗?风流总被雨打风吹去,滴滴是二龙山,三虫聚首?是不是正确的事情不知道,反正跟着公司大势所趋,升D10保平安。
Factorization Machines(FM) 由日本 Osaka University 的 Steffen Rendle [1] 在 2010 年提出,是一种常用的因子机模型。
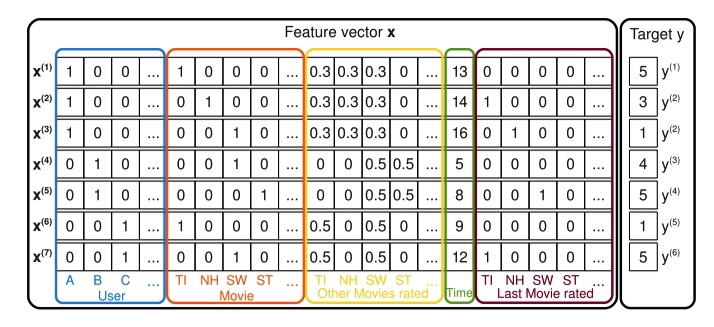
假设现在有一个电影评分的任务,给定如下如所示的特征向量 x(包括用户名、当前在看的电影、已经打分的电影、时间特征、之前看的电影),预测用户对当前观看电影的评分。
作者在线性回归模型的基础上,添加交叉项部分,用来自动组合二阶特征。
$$\hat y(x):= w_0 + \sum_{i=1}^{n} w_ix_i + \sum_{i=1}^n \sum_{j=i+1}^n \left \langle v_i,v_j \right \rangle x_ix_j$$
其中交叉特征的权重由两个向量的点积得到,可以解决没有在模型中出现的特征组合权重问题,以及减少参数数量。
$$W_{i,j}=\left \langle v_i,v_j \right \rangle = \sum_{f=1}^kv_{i,f} \cdot v_{j,f}$$
通过下面的方法来化简交叉项权重计算,算法复杂度降到线性。
$$\sum_{i=1}^n \sum_{j=i+1}^n \left \langle v_i,v_j \right \rangle x_iy_i = \frac{1}{2}\sum^k_{f=1} \left( \left(\sum_{i=1}^nv_{i,f}x_i \right)^2 - \sum^n_{i=1} v^2_{i,f} x_i^2 \right)$$
对交叉项部分的求导:
$$\frac{\partial}{\partial \theta} \hat y \left( x \right) =
\begin{cases}
1, & \text{ if $\theta$ is $w_0$} \
x_i, & \text{ if $\theta$ is ${w_i}$} \
x_i\sum^n_{j=1} v_{j,f}x_j - v_{i,f}x_i^2, &\text{if $\theta$ is ${v_{i,f}}$}
\end{cases}$$
其中 ${\sum^n_{j=1} v_{j,f}x_j}$ 与 ${x_i}$ 无关,可以在计算导数前预处理出来。
对于经典的特征组合问题,不难想到使用 SVM 求解。Steffen 在论文中也多次将 FM 和 SVM 做对比。
在考虑 SVM 的 Polynomial kernel 为 ${K(\mathbf{x}, \mathbf{z}) :=(\langle\mathbf{x}, \mathbf{z}\rangle+ 1)^{2}}$,映射
$$
\begin{array}{l}{\phi(\mathbf{x}) :=\left(1, \sqrt{2} x_{1}, \ldots, \sqrt{2} x_{n}, x_{1}^{2}, \ldots, x_{n}^{2}\right.} {\sqrt{2} x_{1} x_{2}, \ldots, \sqrt{2} x_{1} x_{n}, \sqrt{2} x_{2} x_{3}, \ldots, \sqrt{2} x_{n-1} x_{n} )}\end{array}
$$
SVM 的公式可以转化为:
$$
\begin{aligned} \hat{y}(\mathbf{x})=w_{0}+\sqrt{2} \sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} w_{i, i}^{(2)} x_{i}^{2} &+\sqrt{2} \sum_{i=1}^{n} \sum_{j=i+1}^{n} w_{i, j}^{(2)} x_{i} x_{j} \end{aligned}
$$
论文中提到一句上面的公式中 ${w_{i}}$ 和 ${w_{i,i}}$ 表达能力类似,我猜这也是为什么 FM 中没有自身交叉项的原因吧。
FM 相比于 SVM 有下面三个特点:
FM 用来做回归和分类都很好理解,简单写一下如何应用到排序任务中。以 pairwise 为例。假设排序结果有两个文档 ${x_i}$ 和 ${x_j}$,显然用户点击文档有先后顺序,如果先点击 ${x_i}$,记 label ${y_{ij}=1}$,反之点击 ${x_j}$,label ${y_{ij}=0}$。模型需要去预测 ${\hat y_{ij} = sigmoid(\hat y_i - \hat y_j)}$。
参考逻辑回归,用最大似然对参数进行估计,得到损失函数为 ${L=\log(1+\exp(-(\hat y(x_i)-\hat y(x_j))}$。优化过程和前面提到类似。
NFM 和 AFM 两篇论文是同一个作者写的,所以文章的结构很相近。
FM 模型由于复杂度问题,一般只使用特征二阶交叉的形式,缺少对 higher-order 以及 non-liner 特征的交叉能力。NFM 尝试通过引入 NN 来解决这个问题。
NFM 的结构如下:第一项和第二项是线性回归,第三项是神经网络。神经网络中利用 FM 模型的二阶特征交叉结果做为输入,学习数据之间的高阶特征。与直接使用高阶 FM 模型相比,可以降低模型的训练复杂度,加快训练速度。
$$
\hat{y}{N F M}(\mathbf{x})=w{0}+\sum_{i=1}^{n} w_{i} x_{i}+f(\mathbf{x})
$$
NFM 的神经网络部分包含 4 层,分别是 Embedding Layer、Bi-Interaction Layer、Hidden Layers、Prediction Score。
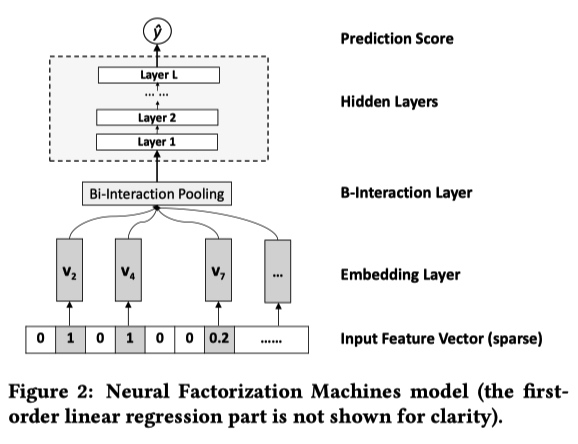
$$
f_{B I}\left(\mathcal{V}{x}\right)=\sum{i=1}^{n} \sum_{j=i+1}^{n} x_{i} \mathbf{v}{i} \odot x{j} \mathbf{v}{j} =\frac{1}{2}\left[\left(\sum{i=1}^{n} x_{i} \mathbf{v}{i}\right)^{2}-\sum{i=1}^{n}\left(x_{i} \mathbf{v}_{i}\right)^{2}\right]
$$
实验结果:
AFM(Attentional Factorization Machine), 在 FM 的基础上将 Attention 机制引入到交叉项部分,用来区分不同特征组合的权重。
$$
\hat{y}{A F M}(\mathbf{x})=w{0}+\sum_{i=1}^{n} w_{i} x_{i}+\mathbf{p}^{T} \sum_{i=1}^{n} \sum_{j=i+1}^{n} a_{i j}\left(\mathbf{v}{i} \odot \mathbf{v}{j}\right) x_{i} x_{j}
$$
单独看上面公式中的第三项结构:
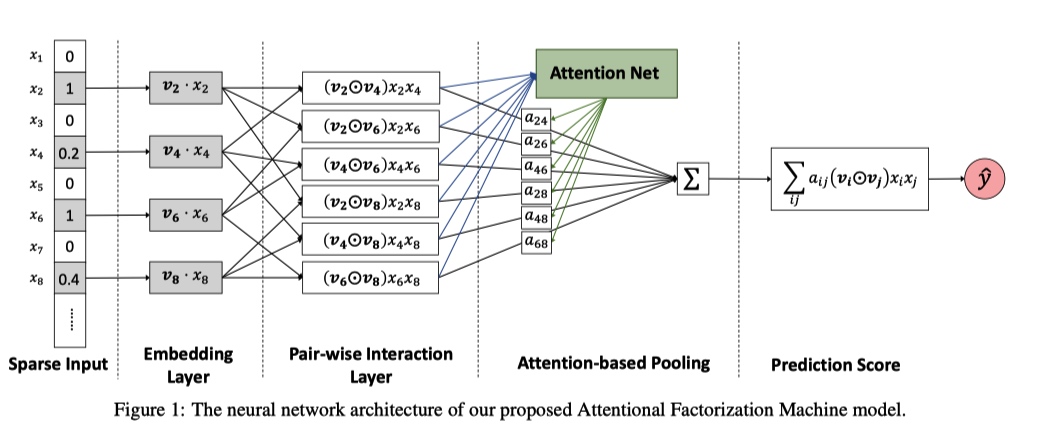
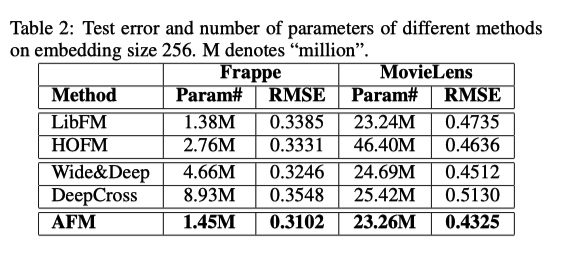
和前一节的实验结果对比,AFM 效果比 NFM 要差一些。这大概就能说明为什么论文中提到 NFM,但是最后没有把 NFM 的结果贴出来,实在是机智。又回到,发论文是需要方法有创新,还是一味追求 state-of-the-art。
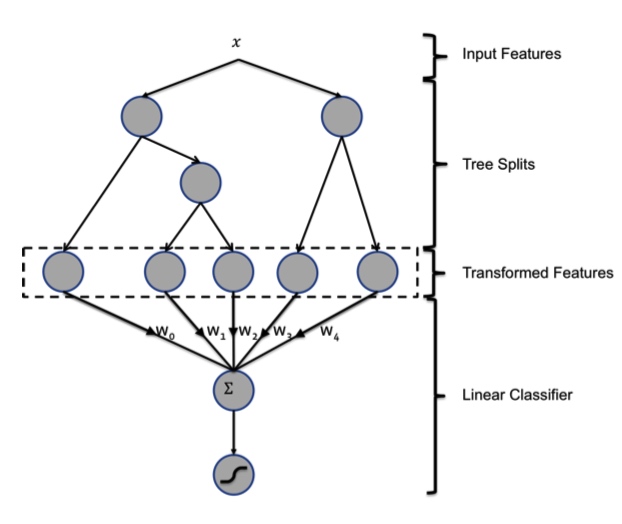
(Wide&Deep) Wide & Deep Learning for Recommender Systems
这是一篇推荐系统相关的论文,场景是谷歌 Play Store 的 App 推荐。文章开头,作者点明推荐系统需要解决的两个能力: memorization 和 generalization。
memorization 指的是学习数据中出现过的组合特征能力。最常使用的算法是 Logistic Regression,简单、粗暴、可解释性强,而且会人工对特征进行交叉,从而提升效果。但是,对于在训练数据中没有出现过的特征就无能为力。
generalization 指的是通过泛化出现过特征从解释新出现特征的能力。常用的是将高维稀疏的特征转换为低维稠密 embedding 向量,然后使用 fm 或 dnn 等算法。与 LR 相比,减少特征工程的投入,而且对没有出现过的组合有较强的解释能力。但是当遇到的用户有非常小众独特的爱好时(对应输入的数据非常稀疏和高秩),模型会过度推荐。
综合前文 ,作者提出一种新的模型 Wide & Deep。
从文章题目中顾名思义,Wide & Deep 是融合 Wide Models 和 Deep Models 得到,下图形象地展示出来。
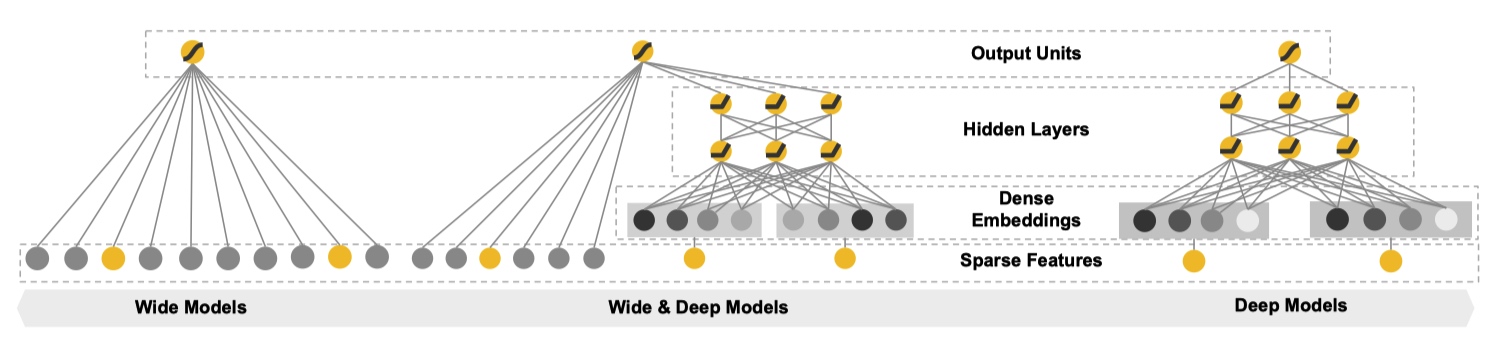
Wide Component 是由一个常见的广义线性模型:${y=w^Tx+b}$。其中输入的特征向量 ${x}$ 包括两种类型:原始输入特征(raw input features)和组合特征(transformed features)。
常用的组合特征公式如下:
$${\phi_k(x)=\prod_{i=1}^dx_i^{c_{ki}},c_{ki}\in{0,1}}$$
${c_{ki}}$ 代表对于第k个组合特征是否包含第i个特征。${x_i}$是布尔变量,代表第i个特征是否出现。例如对于组合特征 AND(gender=female, language=en) 当且仅当 x 满足(“gender=female” and “language=en”)时,${\phi_k(x)=1}$。
Deep Component 是一个标准的前馈神经网络,每一个层的形式诸如:${a^{(l+1)}=f(W^{(l)}a^{(l)} + b^{(l)})}$。对于输入中的 categorical feature 需要先转化成低维稠密的 embedding 向量,再和其他特征一起喂到神经网络中。
对于这种由基础模型组合得到的新模型,常用的训练形式有两种:joint training 和 ensemble。ensemble 指的是,不同的模型单独训练,且不共享信息(比如梯度)。只有在预测时根据不同模型的结果,得到最终的结果。相反,joint training 将不同的模型结果放在同一个损失函数中进行优化。因此,ensmble 要且模型独立预测时就有有些的表现,一般而言模型会比较大。由于 joint training 训练方式的限制,每个模型需要由不同的侧重。对于 Wide&Deep 模型来说,wide 部分只需要处理 Deep 在低阶组合特征学习的不足,所以可以使用简单的结果,最终完美使用 joint traing。
预测时,会将 Wide 和 Deep 的输出加权得到结果。在训练时,使用 logistic loss function 做为损失函数。模型优化时,利用 mini-batch stochastic optimization 将梯度信息传到 Wide 和 Deep 部分。然后,Wide 部分通过 FTRL + L1 优化,Deep 部分通过 AdaGrad 优化。
本篇论文选择的实验场景是谷歌 app 商店的应用推荐,根据用户相关的历史信息,推荐最有可能会下载的 App。
使用的模型如下:
一些细节:
实验结果:
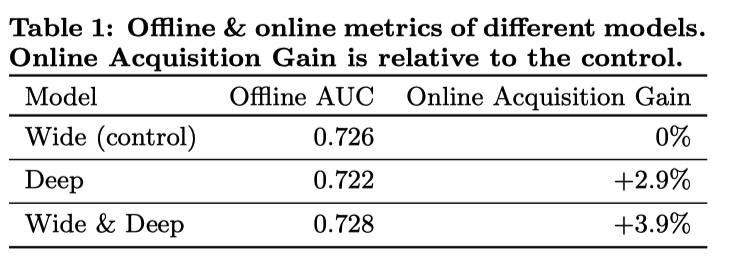
Wide & Deep 模型相对于其他两个模型毫无疑问有提升。但结果中也一个反常的现象:单独使用 Deep 模型离线 AUC 指标比单独使用 Wide 模型差,但是线上对比实验时却有较大的提升。论文中作者用了一句:线下实验中的特征是固定的,线上实验会遇到很多没有出现过的特征组合,Deep 相对于 Wide 有更好的模型泛化能力,所以会有反常现象。由于笔者工作中不关注 AUC,也没有办法继续分析。
作者从推荐系统的的 memorization 和 generalization 入手,设计出新的算法框架。通过线上和线下实验实验,证明 Deep 和 Wide 联合是必须的且有效的。最终也在自己的业务场景带来提升。
Practical Lessons from Predicting Clicks on Ads at Facebook(gbdt + lr)
主题:Facebook 2014 年发表的广告点击预测文章。最主要是提出经典 GBDT+LR 模型,可以自动实现特征工程,效果好比于人肉搜索。另外,文章中还给出一个 online learning 的工程框架。
问题:
收获:
利用 GBDT 模型进行自动特征组合和筛选,然后根据样本落在哪棵树哪个叶子生成一个 feature vector 输入到 LR 模型中。这种方法的有点在于两个模型在训练过程从是独立,不需要进行联合训练。
GBDT 由多棵 CART 树组成,每一个节点按贪心分裂。最终生成的树包含多层,相当于一个特征组合的过程。根据规则,样本一定会落在一个叶子节点上,将这个叶子节点记为1,其他节点设为0,得到一个向量。比如下图中有两棵树,第一棵树有三个叶子节点,第二棵树有两个叶子节点。如果一个样本落在第一棵树的第二个叶子,将它编码成 [0, 1, 0]。在第二棵树落到第一个叶子,编码成 [1, 0]。所以,输入到 LR 模型中的向量就是 [0, 1, 0, 1, 0]
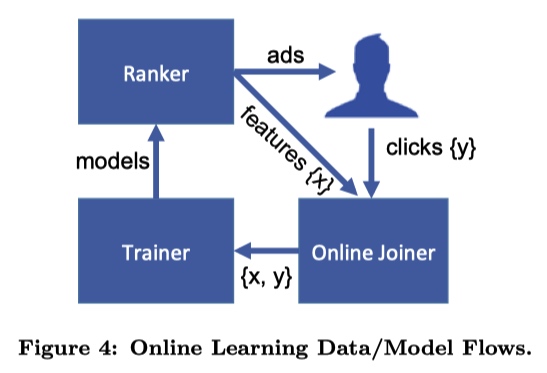
文章中提到的 Online Learning 包括三个部分:
注意的点:
训练两个 LR 模型,一个模型输入样本经过 GBDT 得到的特征,另外一个不输入。混合模型比单独 LR 或 Tree
5 种学习率,前三个每一个特征设置一个学习率,最后两种全局学习率。
结果:应该给每一个特征设置一个不同的学习率,而且学习率应该随着轮次缓慢衰减。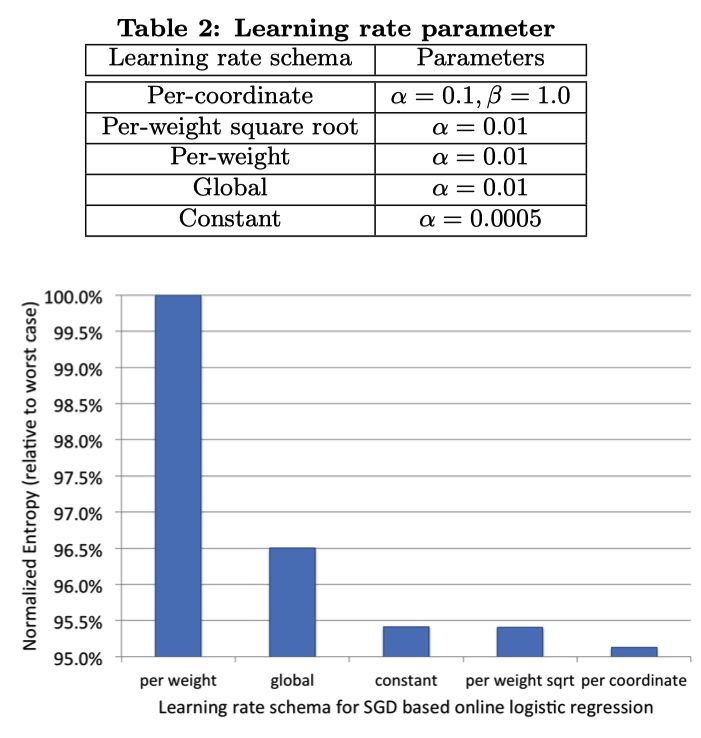
训练数据大多,需要进行采样。
uniform subsampling :无差别采样。使用 10 % 的样本,NE 减少 1 %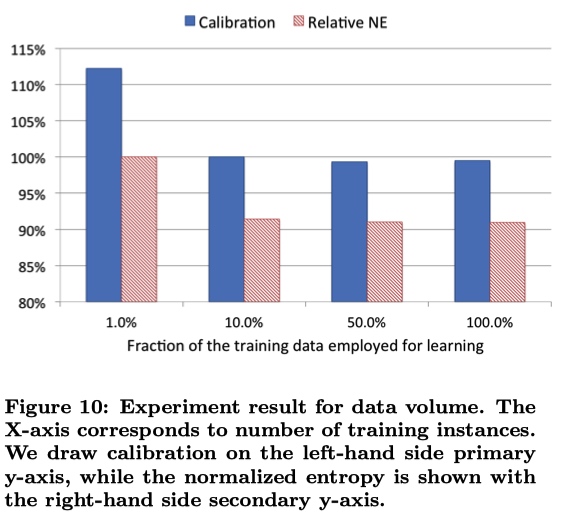
negative down subsampling :对负样本进行下采样。但不是负采样率越低越好,比如下面的图中0.0250就可能是解决了正负样本不平衡问题。最后的CTR指标结果需要重新进行一次映射。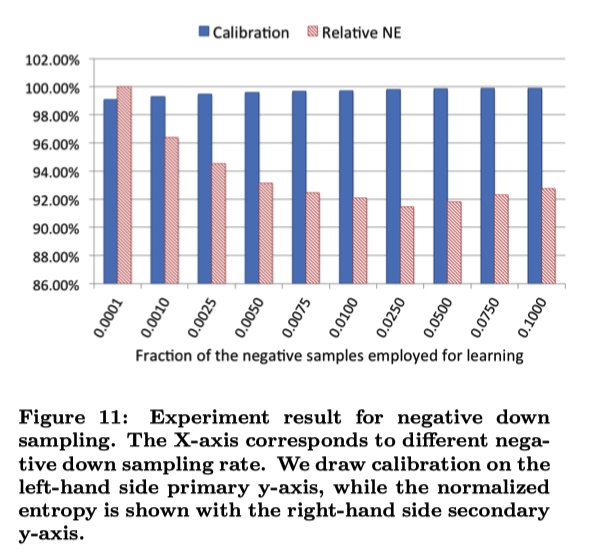
ImageNet Classification with Deep Convolutional Neural Networks(AlexNet)
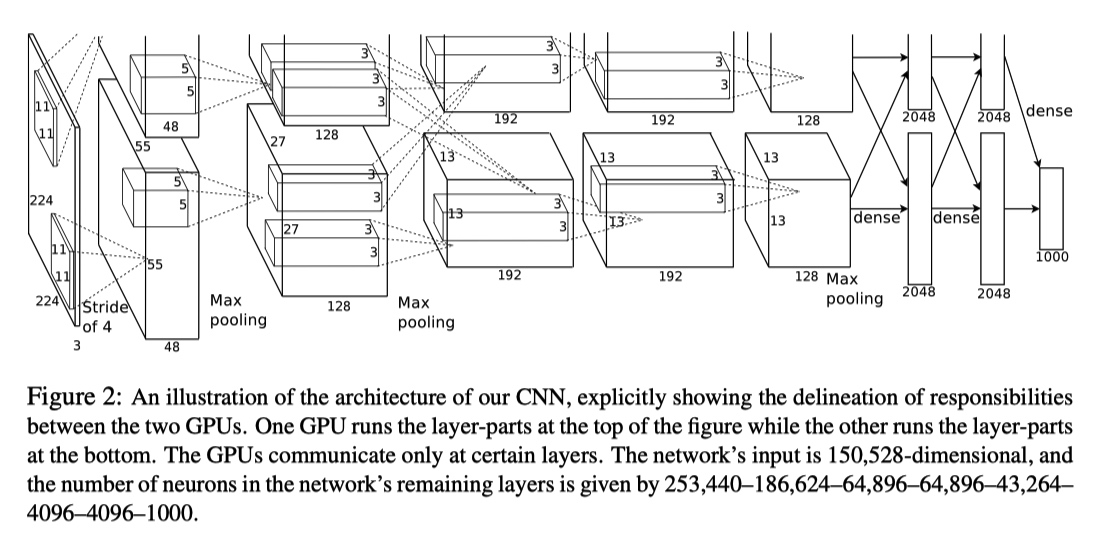
由于当时的 GPU 显存限制,无法将所有的数据加载到单独 GPU 中,作者使用两个 GPU 并行训练。
整个模型如下图所示,由 5 个卷积层以及 3 个全连接层组成。其中在 CONV3、FC1、FC2、FC3 层进行两个 GPU 的数据交互。
参数数量 60 million
$$
b_{x, y}^{i}=a_{x, y}^{i} /\left(k+\alpha \sum_{j=\max (0, i-n / 2)}^{\min (N-1, i+n / 2)}\left(a_{x, y}^{j}\right)^{2}\right)^{\beta}
$$
参数:dropout 0.5,batch size 128, SGD Momentum 0.9, Learning rate 1e-2 reduce by 10,L2 weight decay 5e-4
测试集上结果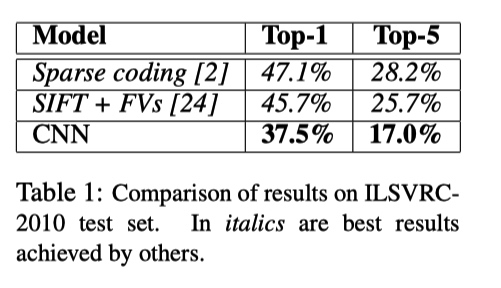
取出 CONV1 相关的 filters卷积侧重点不同,GPU1 颜色无关,GPU2 颜色相关。多次实验发现都存在这种现象,说明使用多个 GPU 训练是必要的,模型可以捕捉更多信息。
取所有最后一个隐层向量,找到与测试图片欧拉距离最小的训练图片(下图中第一列为测试图片,之后几列是欧拉距离最小的训练集中图片)。肉眼可以发现,同一分类的图片有很大关联性。证明模型能学习图片之间的关系。
西瓜书 周志华 2016 年 12 月第 14 次印刷
线性模型的预测函数为:
$${f(x)=w_1x_1+w_2x_2+…+w_dx_d+b}$$
写成向量模式得到:
$${f(x)=w^Tx+b}$$
线性回归能在给定数据集 ${D={(x_1,y_1),(x_2,y_2),…,(x_m,y_m)}}$,其中 ${x_i ={x_{i1};x_{i2};…;x_{id}},y_i\in\mathbb{R}}$学到一个线性模型从而进行预测。
考虑最简单情况,当 ${x_i}$ 为一维时,问题转换为求下式:
$${f(x_i)=wx_i+b}$$
使得
$${f(x_i)\simeq y_i}$$
使用平方损失函数作为衡量线性规划模型性能的指标,${f(x)}$ 与 ${y}$ 越接近,代表平方损失函数越小。即得到: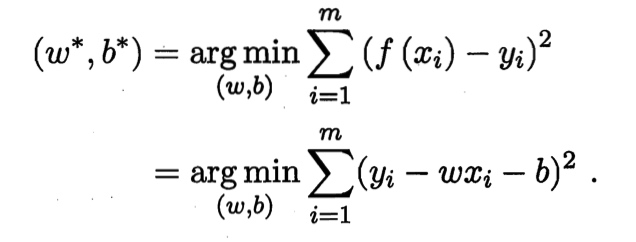
西瓜书 周志华 2016 年 12 月第 14 次印刷
机器学习:利用经验来决策
根据数据是否拥有标记信息分类:
假设空间指的是所有跟问题相关的假设所组成的空间,学习过程是从假设空间中进行搜索,目标是找到与训练集「匹配」(fit)的假设。
在这么多的假设中,可能存在一些假设,得出的结果和训练集一致,这些假设组成的空间叫做「版本空间」(version space)。
对于数据集中没有出现过的情况,算法可能会按照自己的偏好来预测结果,这种情况称为「归纳偏好」。为算法选取偏好时,可以使用「奥卡姆剃刀」原则,即有多个假设与观察一致,则选最简单的那个。但是什么是最简单的也需要仔细思考。
其他科学研究中采用的假设选择原则
古希腊哲学家伊壁鸠鲁 「多释原则」:保留与经验观察一致的原则。